We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
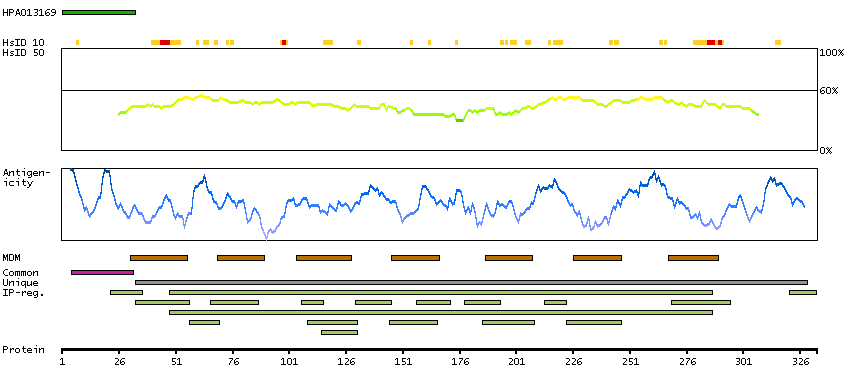
The protein encoded by this gene is a chemokine receptor belonging to the G protein-coupled receptor superfamily. The family members are characterized by the presence of 7 transmembrane domains and numerous conserved amino acids. This receptor is most closely related to RBS11 and the MIP1-alpha/RANTES receptor. It transduces a signal by increasing the intracellular calcium ions level. The viral macrophage inflammatory protein-II is an antagonist of this receptor and blocks signaling. Two alternatively spliced transcript variants encoding the same protein have been found for this gene. [provided by RefSeq, Jul 2008]