We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
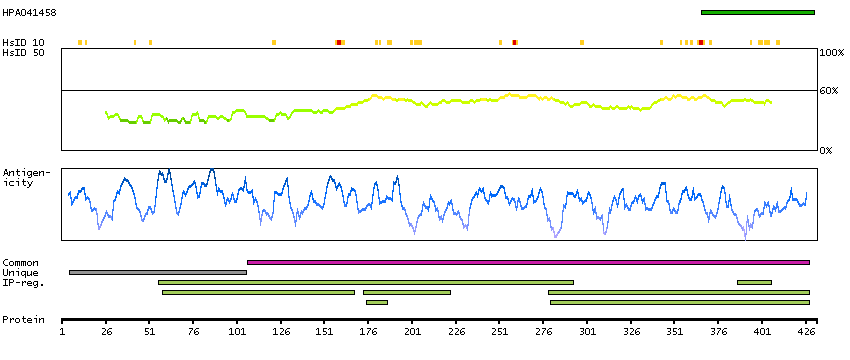
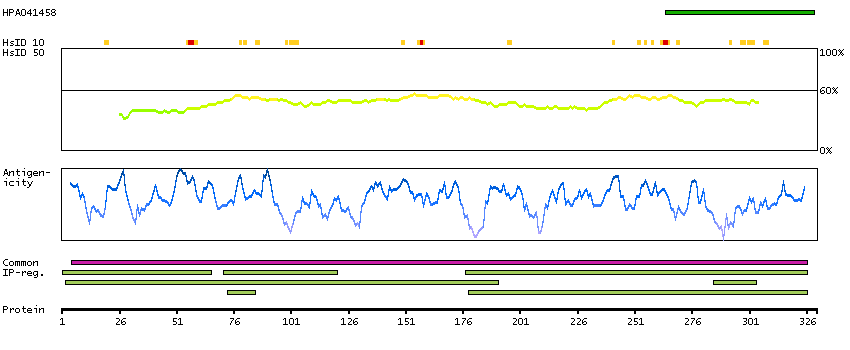
Short/branched chain acyl-CoA dehydrogenase(ACADSB) is a member of the acyl-CoA dehydrogenase family of enzymes that catalyze the dehydrogenation of acyl-CoA derivatives in the metabolism of fatty acids or branch chained amino acids. Substrate specificity is the primary characteristic used to define members of this gene family. The ACADSB gene product has the greatest activity towards the short branched chain acyl-CoA derivative, (S)-2-methylbutyryl-CoA, but also reacts significantly with other 2-methyl branched chain substrates and with short straight chain acyl-CoAs. The cDNA encodes for a mitochondrial precursor protein which is cleaved upon mitochondrial import and predicted to yield a mature peptide of approximately 43.7-KDa. [provided by RefSeq, Jul 2008]
P45954 [Direct mapping] Short/branched chain specific acyl-CoA dehydrogenase, mitochondrial
Show all
Enzymes ENZYME proteins Oxidoreductases MEMSAT-SVM predicted membrane proteins SPOCTOPUS predicted membrane proteins Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000062 [fatty-acyl-CoA binding] GO:0003995 [acyl-CoA dehydrogenase activity] GO:0005739 [mitochondrion] GO:0005759 [mitochondrial matrix] GO:0006631 [fatty acid metabolic process] GO:0008152 [metabolic process] GO:0009055 [electron carrier activity] GO:0009083 [branched-chain amino acid catabolic process] GO:0016627 [oxidoreductase activity, acting on the CH-CH group of donors] GO:0033539 [fatty acid beta-oxidation using acyl-CoA dehydrogenase] GO:0034641 [cellular nitrogen compound metabolic process] GO:0044281 [small molecule metabolic process] GO:0050660 [flavin adenine dinucleotide binding] GO:0052890 [oxidoreductase activity, acting on the CH-CH group of donors, with a flavin as acceptor] GO:0055088 [lipid homeostasis] GO:0055114 [oxidation-reduction process] GO:0070062 [extracellular exosome]