We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
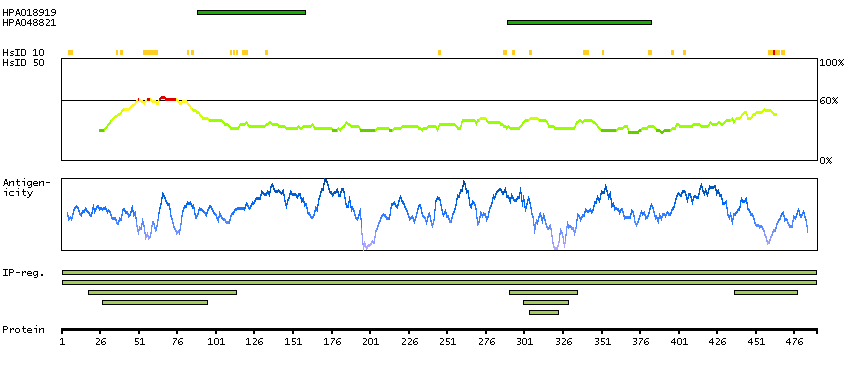
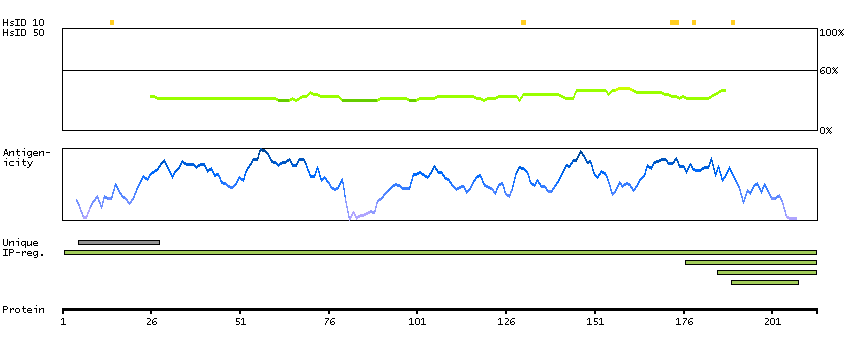
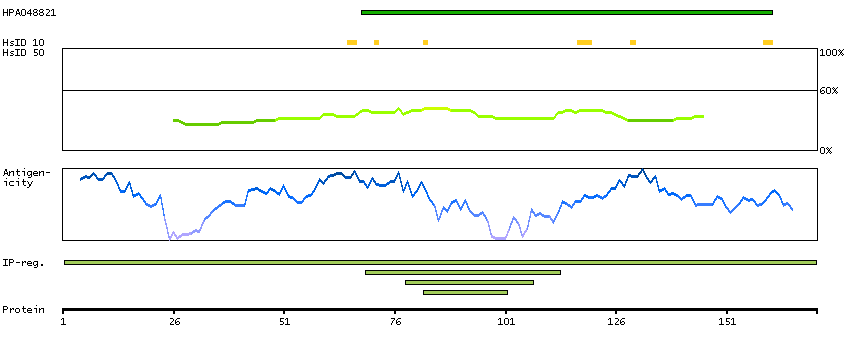
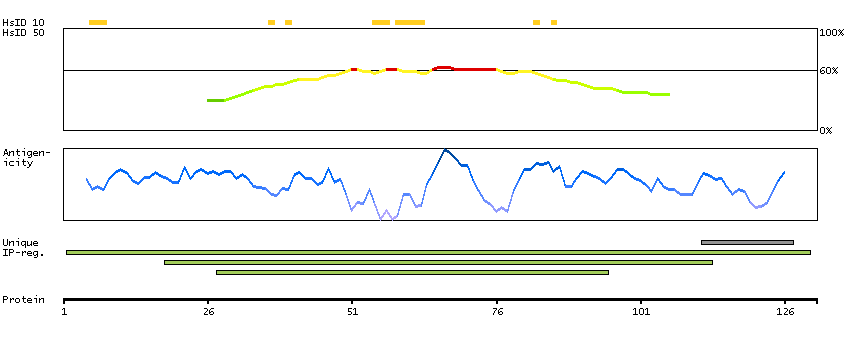
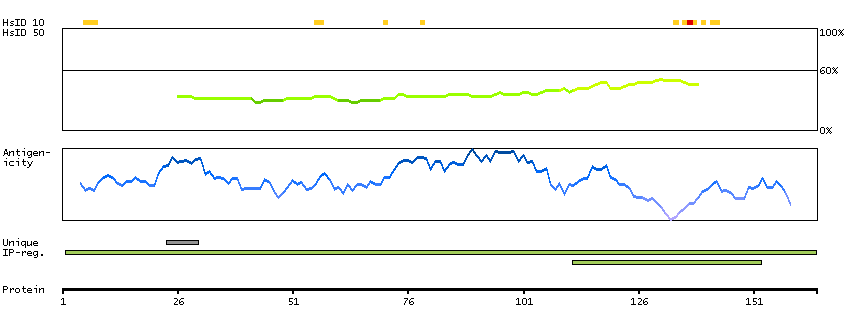
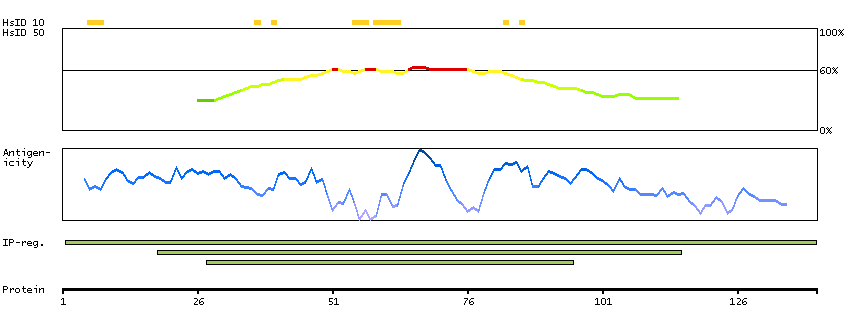
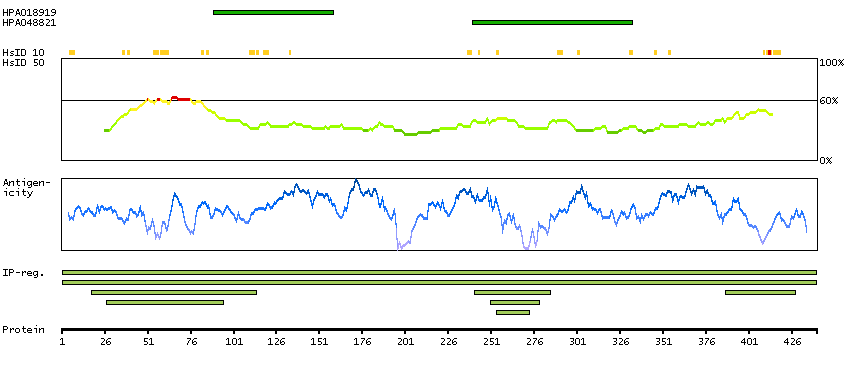
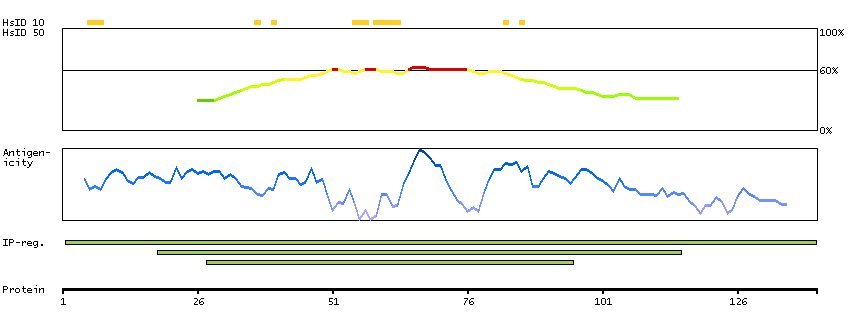
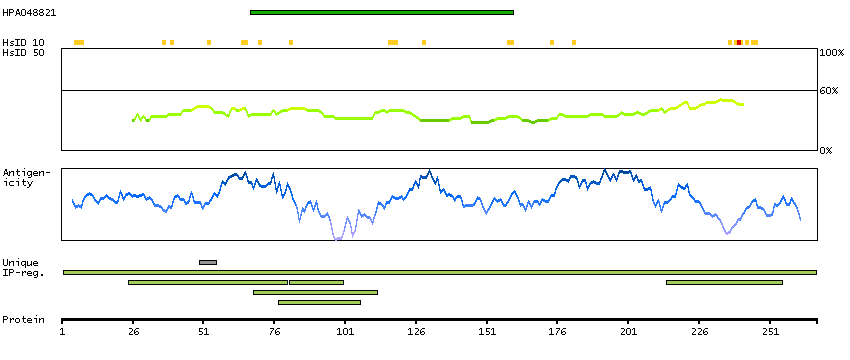
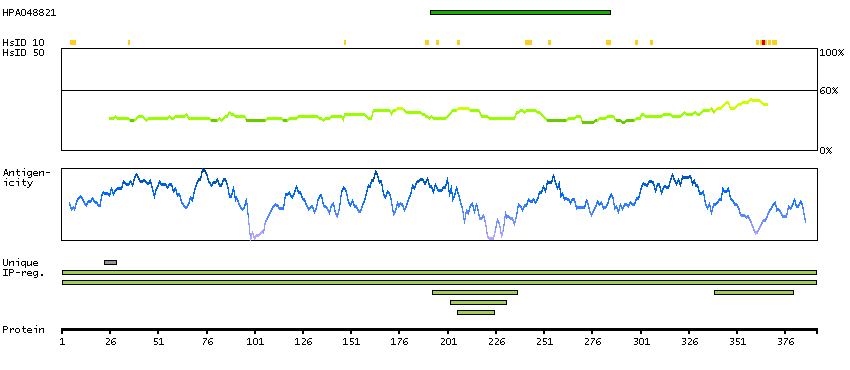
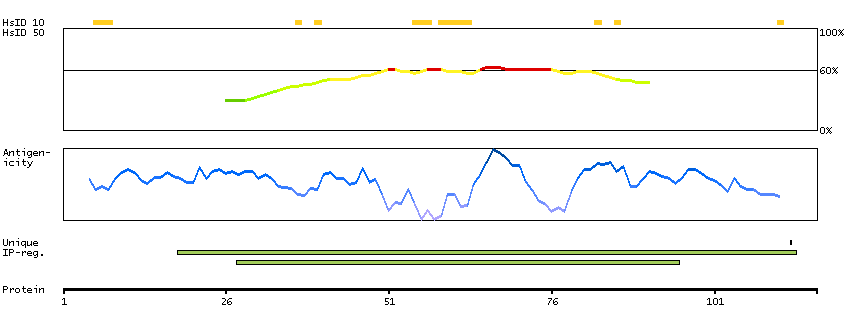
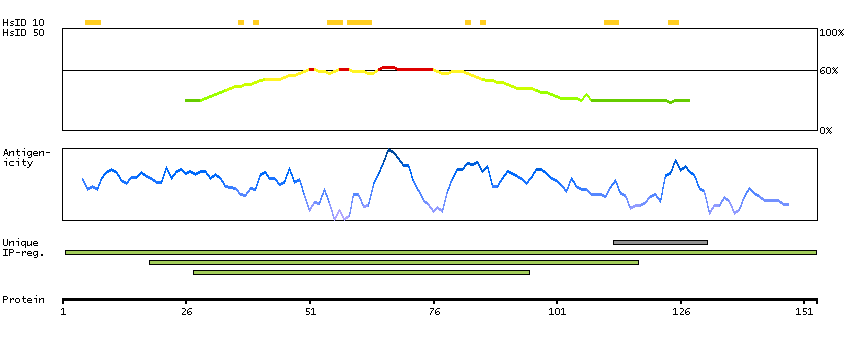
This gene encodes a nuclear protein that contains a p53 binding domain at the N-terminus and a RING finger domain at the C-terminus, and shows structural similarity to p53-binding protein MDM2. Both proteins bind the p53 tumor suppressor protein and inhibit its activity, and have been shown to be overexpressed in a variety of human cancers. However, unlike MDM2 which degrades p53, this protein inhibits p53 by binding its transcriptional activation domain. This protein also interacts with MDM2 protein via the RING finger domain, and inhibits the latter's degradation. So this protein can reverse MDM2-targeted degradation of p53, while maintaining suppression of p53 transactivation and apoptotic functions. Alternatively spliced transcript variants encoding different isoforms have been noted for this gene. [provided by RefSeq, Feb 2011]
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations Protein evidence (Kim et al 2014)
Show all
GO:0000122 [negative regulation of transcription from RNA polymerase II promoter] GO:0002027 [regulation of heart rate] GO:0003170 [heart valve development] GO:0003181 [atrioventricular valve morphogenesis] GO:0003203 [endocardial cushion morphogenesis] GO:0003281 [ventricular septum development] GO:0003283 [atrial septum development] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0006461 [protein complex assembly] GO:0008270 [zinc ion binding] GO:0008283 [cell proliferation] GO:0008284 [positive regulation of cell proliferation] GO:0008285 [negative regulation of cell proliferation] GO:0019899 [enzyme binding] GO:0030330 [DNA damage response, signal transduction by p53 class mediator] GO:0042177 [negative regulation of protein catabolic process] GO:0043066 [negative regulation of apoptotic process] GO:0045023 [G0 to G1 transition] GO:0050821 [protein stabilization] GO:0071157 [negative regulation of cell cycle arrest] GO:0071456 [cellular response to hypoxia]
Q68DC0 [Direct mapping] MDM4 protein variant G; MDM4 protein variant Y; Protein Mdm4; Putative uncharacterized protein DKFZp781B1423; cDNA FLJ56709, highly similar to Mdm4 protein
Show all
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations Protein evidence (Kim et al 2014)
Show all
GO:0000122 [negative regulation of transcription from RNA polymerase II promoter] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0006461 [protein complex assembly] GO:0008270 [zinc ion binding] GO:0008283 [cell proliferation] GO:0008285 [negative regulation of cell proliferation] GO:0019899 [enzyme binding] GO:0030330 [DNA damage response, signal transduction by p53 class mediator] GO:0042177 [negative regulation of protein catabolic process] GO:0043066 [negative regulation of apoptotic process] GO:0045023 [G0 to G1 transition] GO:0050821 [protein stabilization] GO:0071157 [negative regulation of cell cycle arrest] GO:0071456 [cellular response to hypoxia]
Q68DC0 [Direct mapping] MDM4 protein variant G; MDM4 protein variant Y; Protein Mdm4; Putative uncharacterized protein DKFZp781B1423; cDNA FLJ56709, highly similar to Mdm4 protein
Show all
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations