We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
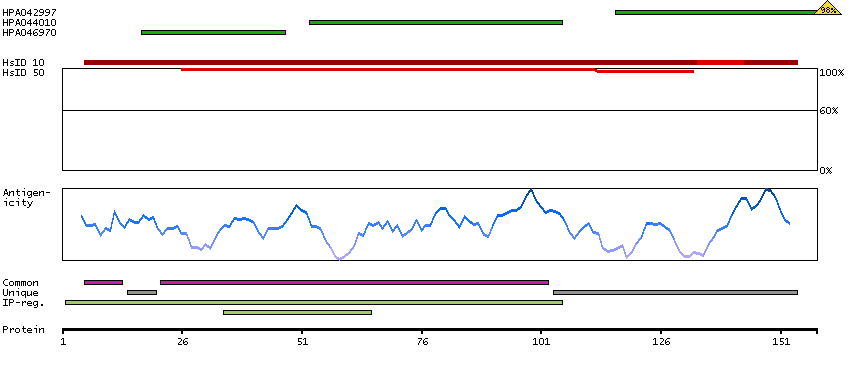
Polymerase (RNA) II (DNA directed) polypeptide J, 13.3kDa (HGNC Symbol)
Entrez gene summary
This gene encodes a subunit of RNA polymerase II, the polymerase responsible for synthesizing messenger RNA in eukaryotes. The product of this gene exists as a heterodimer with another polymerase subunit; together they form a core subassembly unit of the polymerase. Two similar genes are located nearby on chromosome 7q22.1 and a pseudogene is found on chromosome 7p13. [provided by RefSeq, Jul 2008]