We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
The protein encoded by this gene plays a crucial role in B-cell development. Mutations in this gene cause X-linked agammaglobulinemia type 1, which is an immunodeficiency characterized by the failure to produce mature B lymphocytes, and associated with a failure of Ig heavy chain rearrangement. Alternative splicing results in multiple transcript variants encoding different isoforms. [provided by RefSeq, Dec 2013]
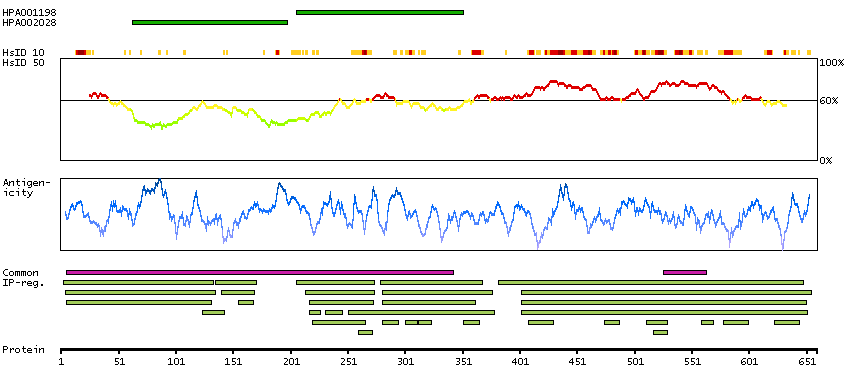
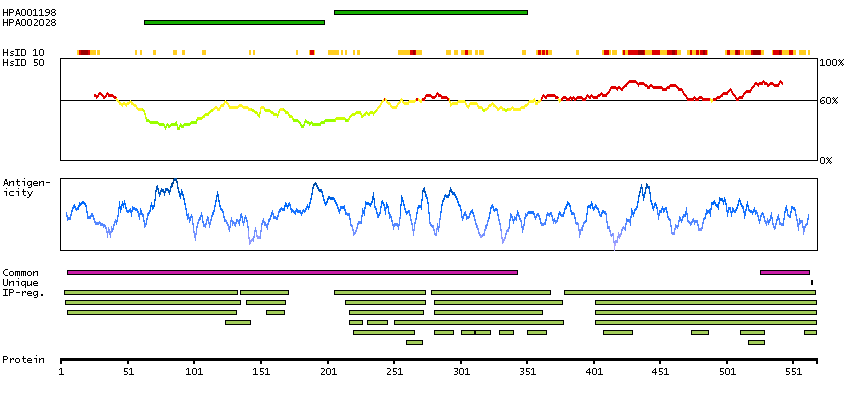
Enzymes ENZYME proteins Transferases Kinases Tyr protein kinases Predicted intracellular proteins Plasma proteins Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
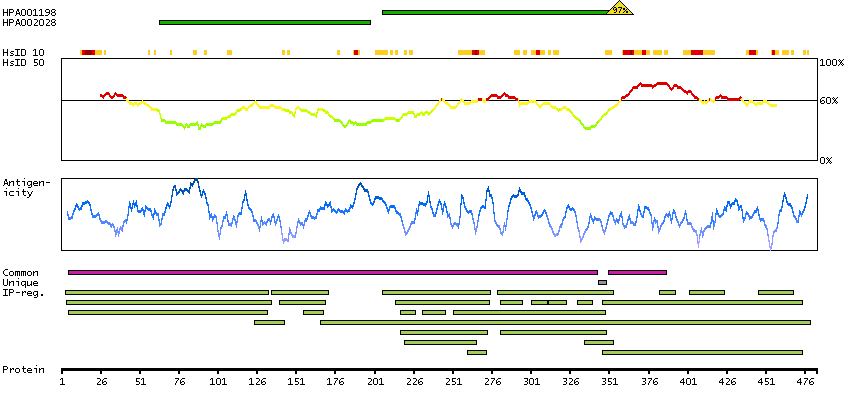
Enzymes ENZYME proteins Transferases Kinases Tyr protein kinases Predicted intracellular proteins Plasma proteins Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Ezkurdia et al 2014)