We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
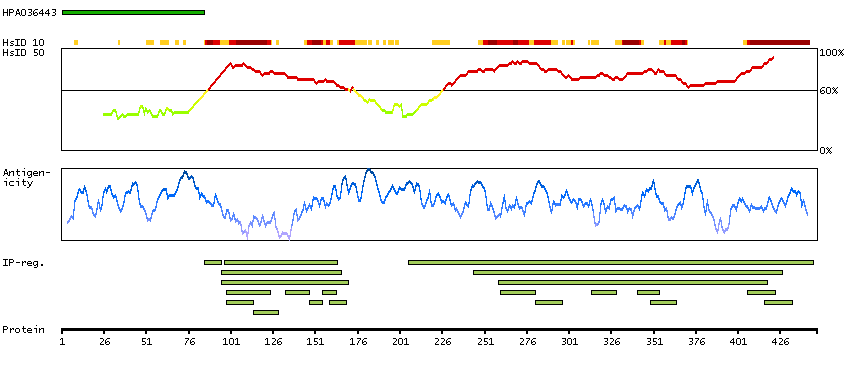
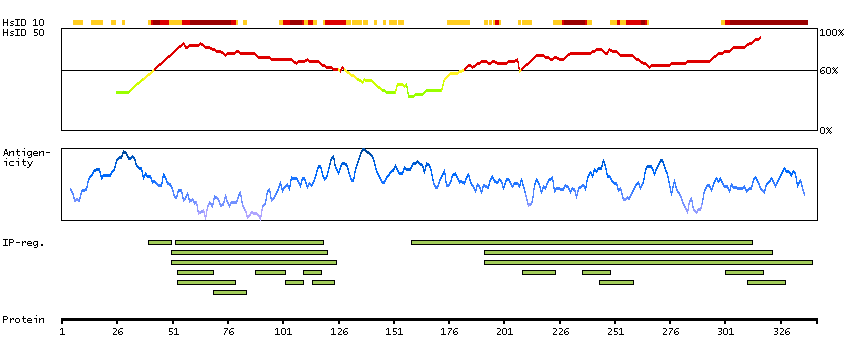
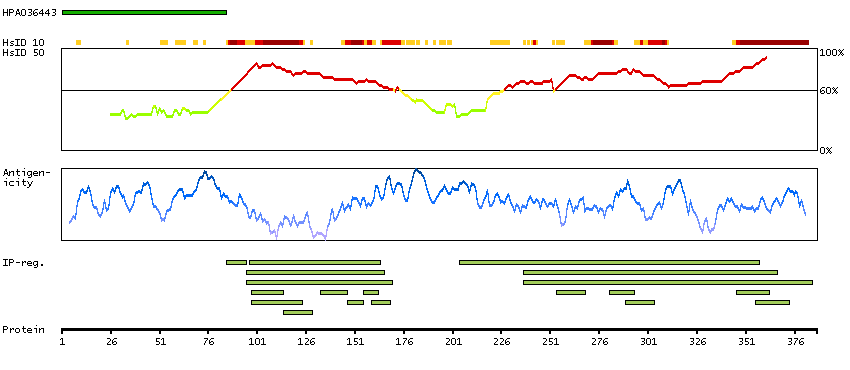
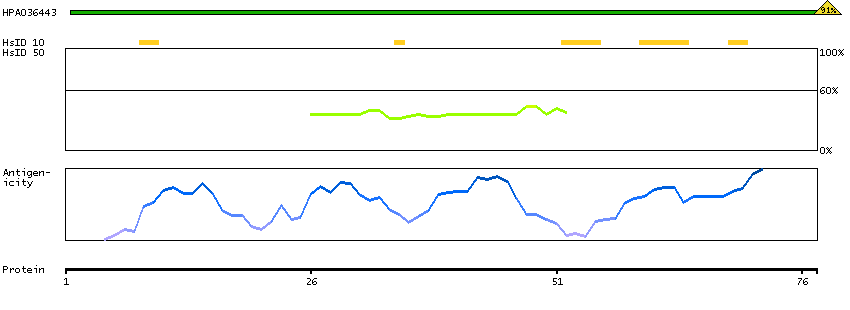
Nuclear receptor subfamily 1, group H, member 3 (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene belongs to the NR1 subfamily of the nuclear receptor superfamily. The NR1 family members are key regulators of macrophage function, controlling transcriptional programs involved in lipid homeostasis and inflammation. This protein is highly expressed in visceral organs, including liver, kidney and intestine. It forms a heterodimer with retinoid X receptor (RXR), and regulates expression of target genes containing retinoid response elements. Studies in mice lacking this gene suggest that it may play an important role in the regulation of cholesterol homeostasis. Alternatively spliced transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Oct 2011]