We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
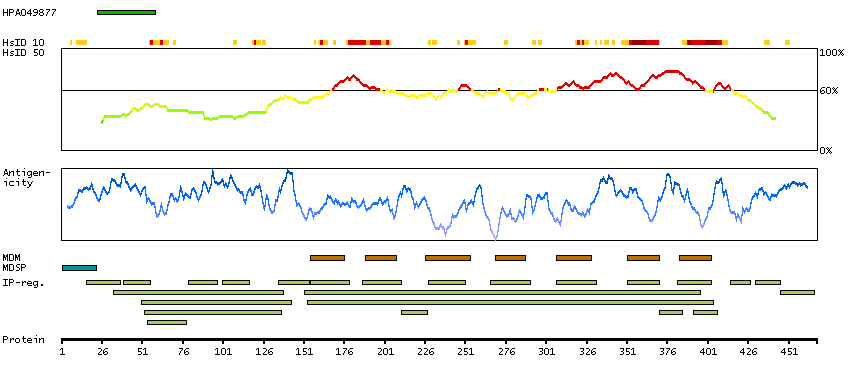
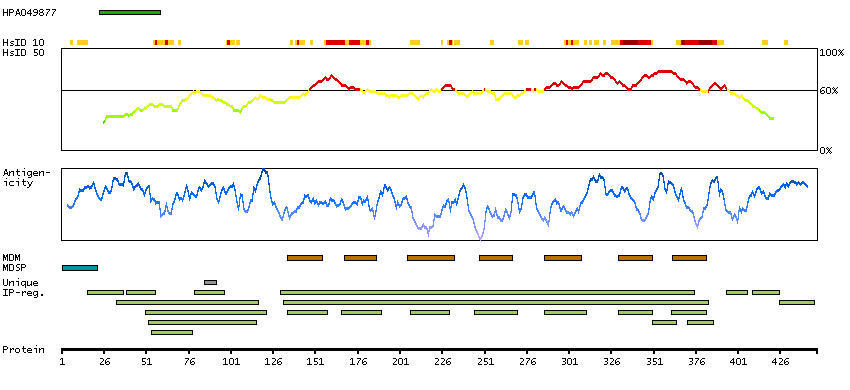
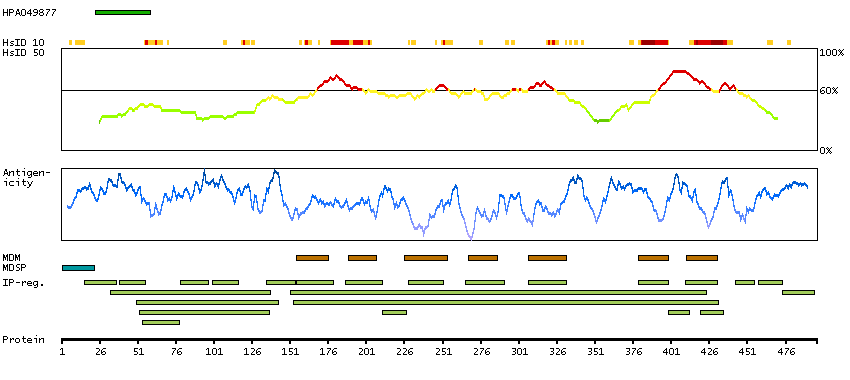
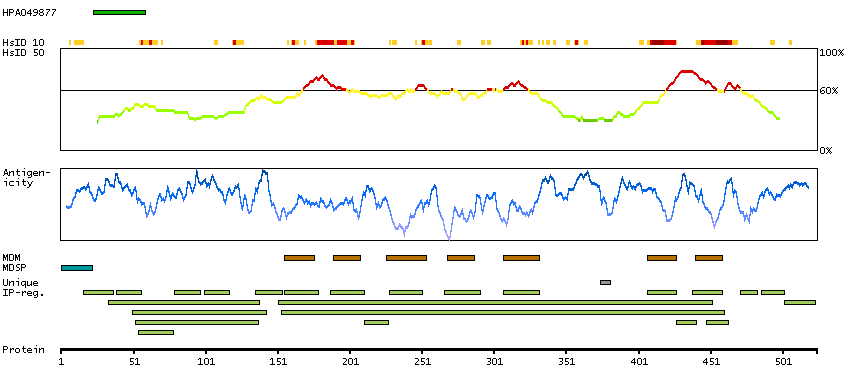
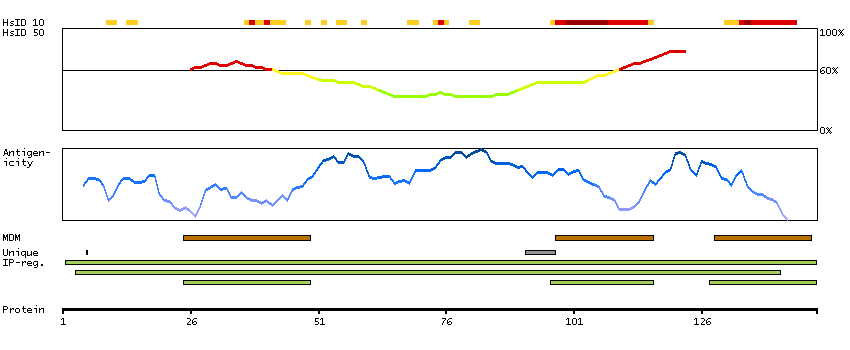
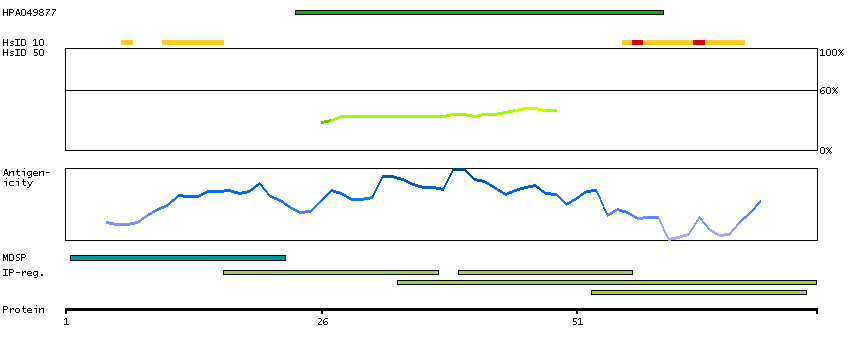
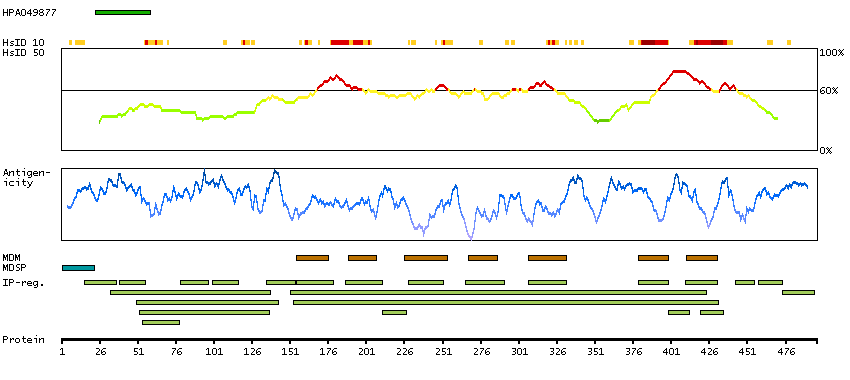
Adenylate cyclase activating polypeptide 1 (pituitary) receptor type I (HGNC Symbol)
Entrez gene summary
This gene encodes type I adenylate cyclase activating polypeptide receptor, which is a membrane-associated protein and shares significant homology with members of the glucagon/secretin receptor family. This receptor mediates diverse biological actions of adenylate cyclase activating polypeptide 1 and is positively coupled to adenylate cyclase. Multiple alternatively spliced transcript variants encoding distinct isoforms have been identified. [provided by RefSeq, Dec 2010]