We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (cervix, uterine, endometrium)
GENE INFORMATION
Gene name
PGR (HGNC Symbol)
Synonyms
NR3C3, PR
Description
Progesterone receptor (HGNC Symbol)
Entrez gene summary
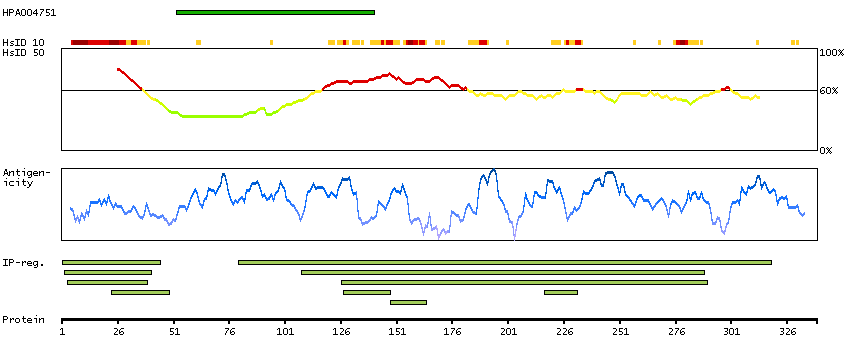
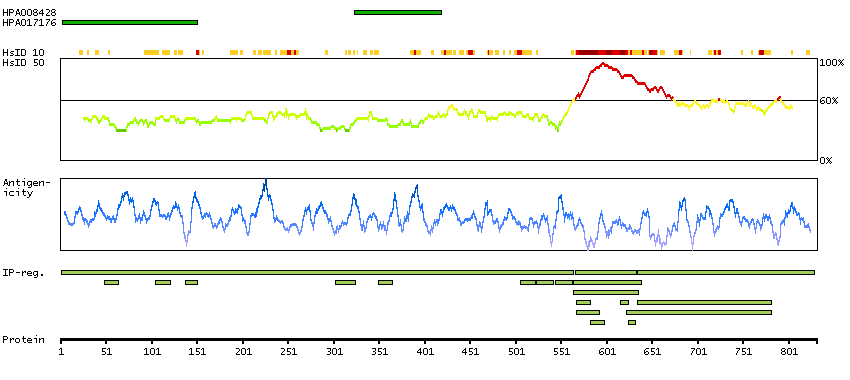
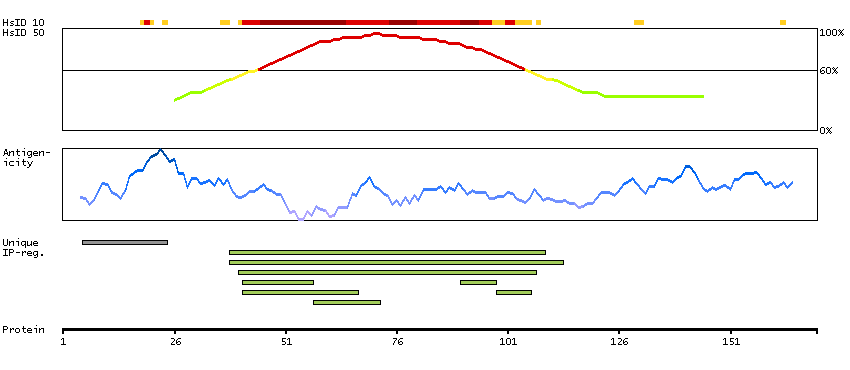
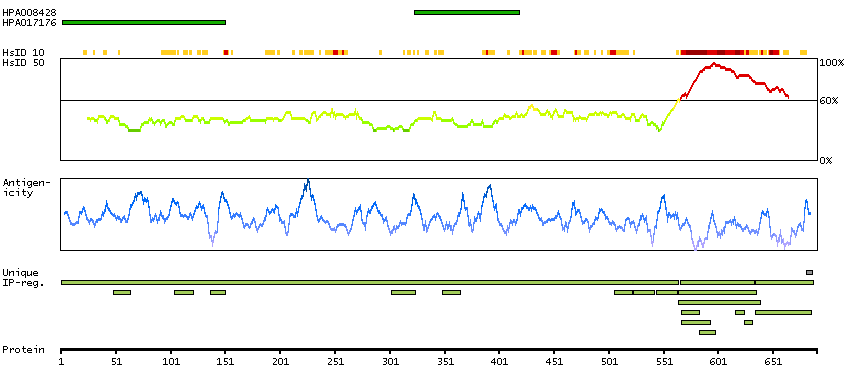
This gene encodes a member of the steroid receptor superfamily. The encoded protein mediates the physiological effects of progesterone, which plays a central role in reproductive events associated with the establishment and maintenance of pregnancy. This gene uses two distinct promotors and translation start sites in the first exon to produce several transcript variants, both protein coding and non-protein coding. Two of the isoforms (A and B) are identical except for an additional 165 amino acids found in the N-terminus of isoform B and mediate their own response genes and physiologic effects with little overlap. [provided by RefSeq, Sep 2015]
Nuclear receptors Phobius predicted membrane proteins Predicted intracellular proteins Transcription factors Zinc-coordinating DNA-binding domains Cancer-related genes Candidate cancer biomarkers FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000978 [RNA polymerase II core promoter proximal region sequence-specific DNA binding] GO:0001077 [transcriptional activator activity, RNA polymerase II core promoter proximal region sequence-specific binding] GO:0001542 [ovulation from ovarian follicle] GO:0002070 [epithelial cell maturation] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0003707 [steroid hormone receptor activity] GO:0004879 [RNA polymerase II transcription factor activity, ligand-activated sequence-specific DNA binding] GO:0005102 [receptor binding] GO:0005496 [steroid binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005741 [mitochondrial outer membrane] GO:0006355 [regulation of transcription, DNA-templated] GO:0006367 [transcription initiation from RNA polymerase II promoter] GO:0007165 [signal transduction] GO:0007267 [cell-cell signaling] GO:0008270 [zinc ion binding] GO:0010467 [gene expression] GO:0010629 [negative regulation of gene expression] GO:0019899 [enzyme binding] GO:0030879 [mammary gland development] GO:0038001 [paracrine signaling] GO:0043401 [steroid hormone mediated signaling pathway] GO:0043565 [sequence-specific DNA binding] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0048286 [lung alveolus development] GO:0050678 [regulation of epithelial cell proliferation] GO:0050847 [progesterone receptor signaling pathway] GO:0051117 [ATPase binding] GO:0060748 [tertiary branching involved in mammary gland duct morphogenesis]
Nuclear receptors Predicted intracellular proteins Transcription factors Zinc-coordinating DNA-binding domains Cancer-related genes Candidate cancer biomarkers FDA approved drug targets Small molecule drugs Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000978 [RNA polymerase II core promoter proximal region sequence-specific DNA binding] GO:0001077 [transcriptional activator activity, RNA polymerase II core promoter proximal region sequence-specific binding] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0005102 [receptor binding] GO:0005496 [steroid binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005741 [mitochondrial outer membrane] GO:0006355 [regulation of transcription, DNA-templated] GO:0006367 [transcription initiation from RNA polymerase II promoter] GO:0007165 [signal transduction] GO:0007267 [cell-cell signaling] GO:0008270 [zinc ion binding] GO:0010467 [gene expression] GO:0010629 [negative regulation of gene expression] GO:0019899 [enzyme binding] GO:0043401 [steroid hormone mediated signaling pathway] GO:0043565 [sequence-specific DNA binding] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0051117 [ATPase binding]