We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
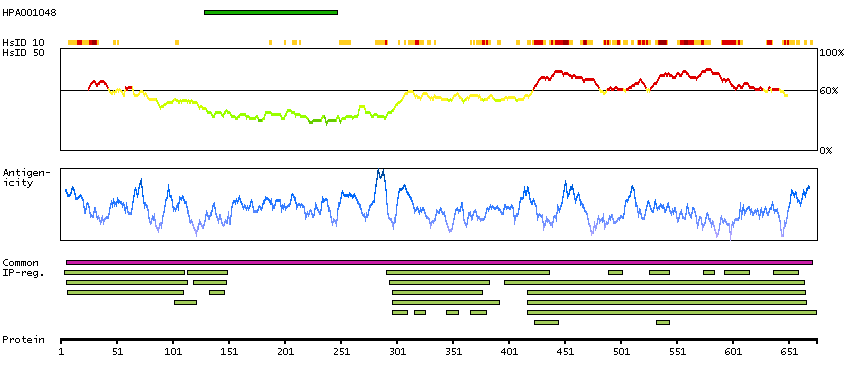
This gene encodes a non-receptor tyrosine kinase belonging to the Tec kinase family. The protein contains a PH-like domain, which mediates membrane targeting by binding to phosphatidylinositol 3,4,5-triphosphate (PIP3), and a SH2 domain that binds to tyrosine-phosphorylated proteins and functions in signal transduction. The protein is implicated in several signal transduction pathways including the Stat pathway, and regulates differentiation and tumorigenicity of several types of cancer cells. Multiple alternatively spliced variants, encoding the same protein, have been identified.[provided by RefSeq, Sep 2009]