We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
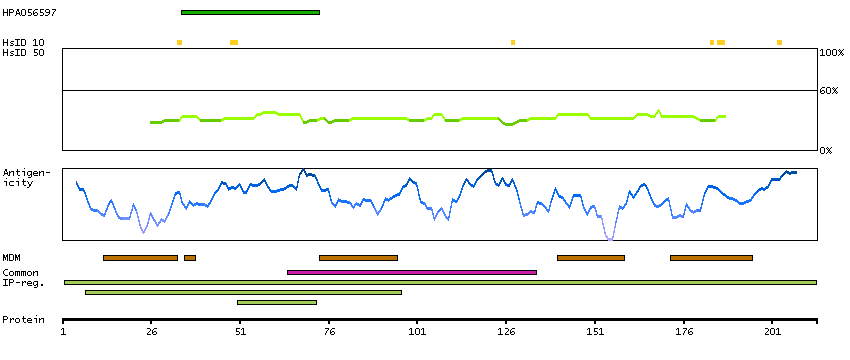
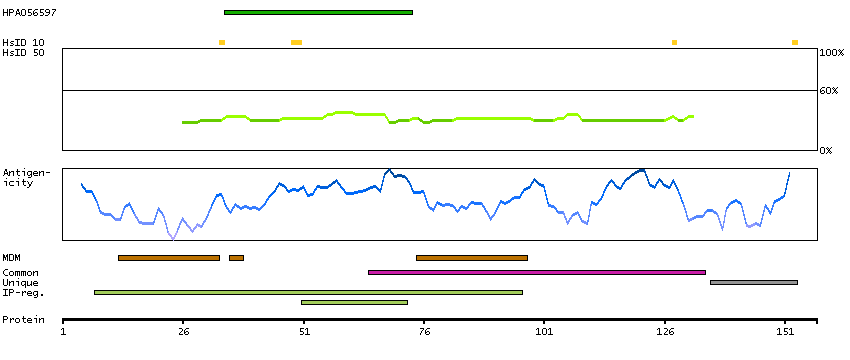
Phosphatidylinositol breakdown products are ubiquitous second messengers that function downstream of many G protein-coupled receptors and tyrosine kinases regulating cell growth, calcium metabolism, and protein kinase C activity. Two enzymes, CDP-diacylglycerol synthase and phosphatidylinositol synthase, are involved in the biosynthesis of phosphatidylinositol. Phosphatidylinositol synthase, a member of the CDP-alcohol phosphatidyl transferase class-I family, is an integral membrane protein found on the cytoplasmic side of the endoplasmic reticulum and the Golgi apparatus. Several transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Nov 2013]