We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
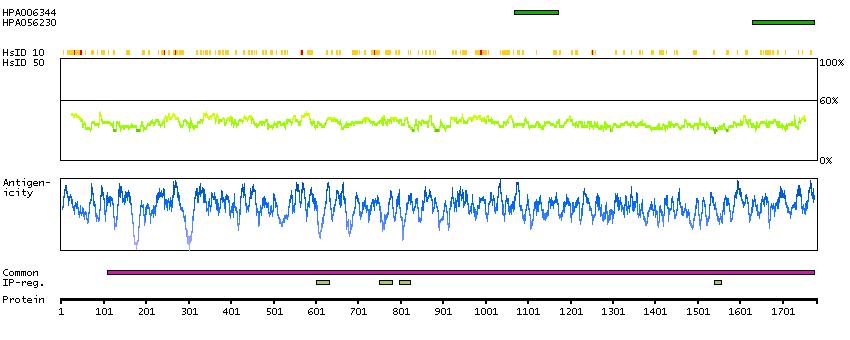
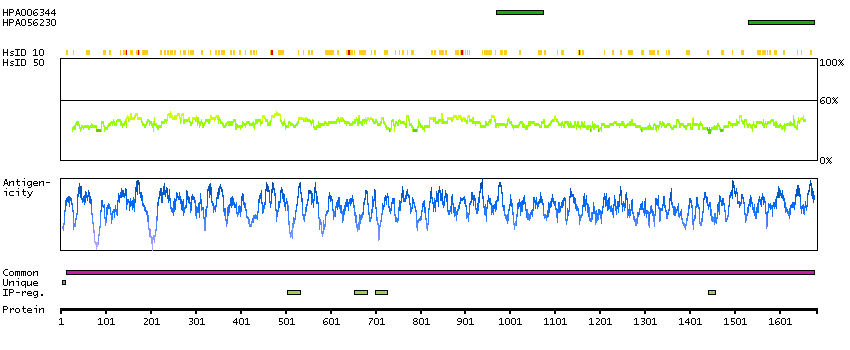
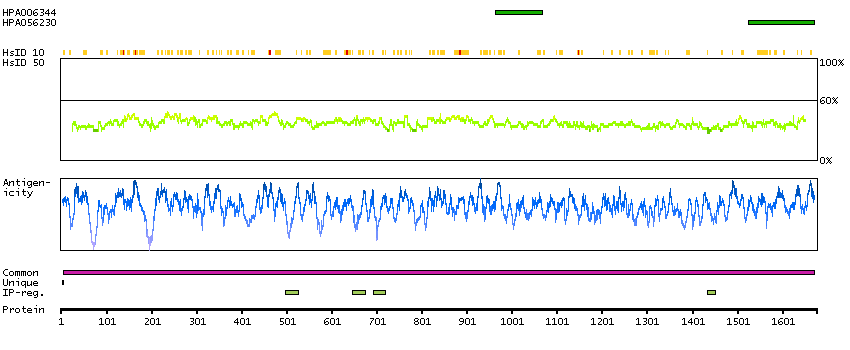
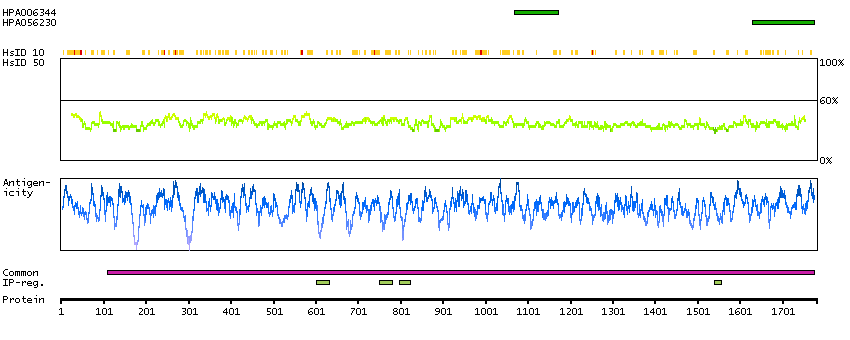
The A-kinase anchor proteins (AKAPs) are a group of structurally diverse proteins, which have the common function of binding to the regulatory subunit of protein kinase A (PKA) and confining the holoenzyme to discrete locations within the cell. This gene encodes a member of the AKAP family. The encoded protein is expressed in endothelial cells, cultured fibroblasts, and osteosarcoma cells. It associates with protein kinases A and C and phosphatase, and serves as a scaffold protein in signal transduction. This protein and RII PKA colocalize at the cell periphery. This protein is a cell growth-related protein. Antibodies to this protein can be produced by patients with myasthenia gravis. Alternative splicing of this gene results in two transcript variants encoding different isoforms. [provided by RefSeq, Jul 2008]
Q02952 [Direct mapping] A-kinase anchor protein 12
Show all
Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Q02952 [Direct mapping] A-kinase anchor protein 12
Show all
Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)