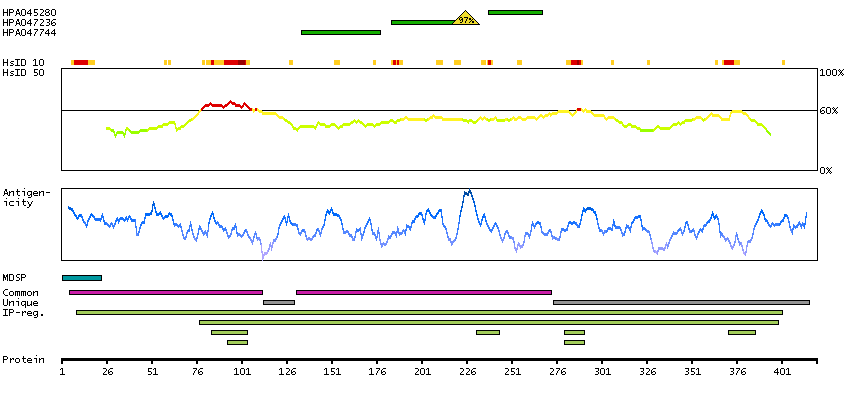
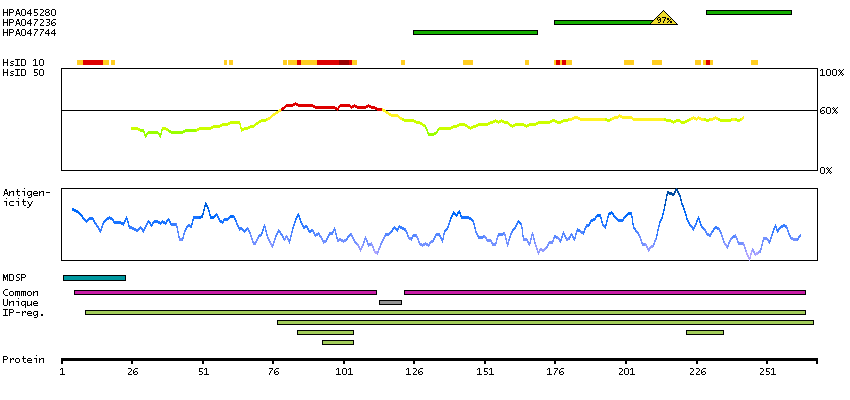
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (kidney, lung)
GENE INFORMATION
Gene name
NAPSA (HGNC Symbol)
Synonyms
KAP, Kdap, NAP1, NAPA
Description
Napsin A aspartic peptidase (HGNC Symbol)
Entrez gene summary
The activation peptides of aspartic proteinases plays role as inhibitors of the active site. These peptide segments, or pro-parts, are deemed important for correct folding, targeting, and control of the activation of aspartic proteinase zymogens. The pronapsin A gene is expressed predominantly in lung and kidney. Its translation product is predicted to be a fully functional, glycosylated aspartic proteinase precursor containing an RGD motif and an additional 18 residues at its C-terminus. [provided by RefSeq, Jul 2008]