We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
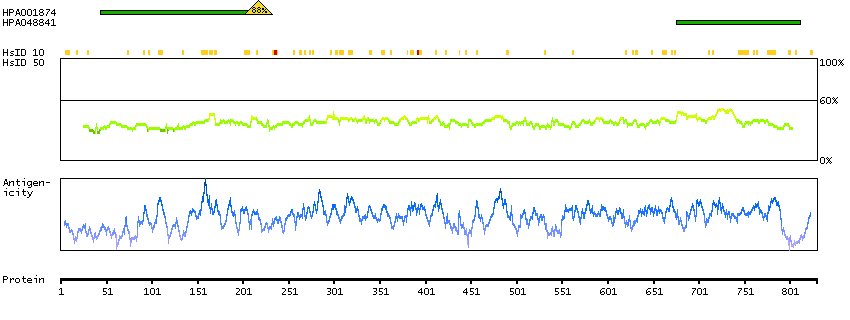
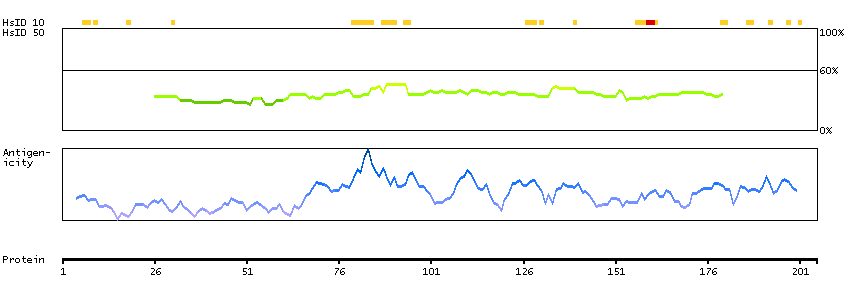
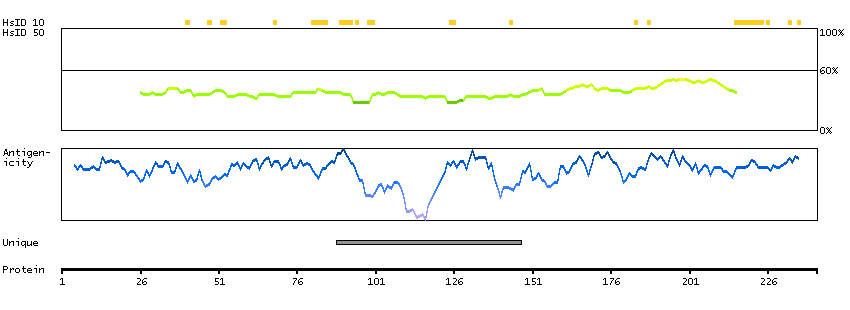
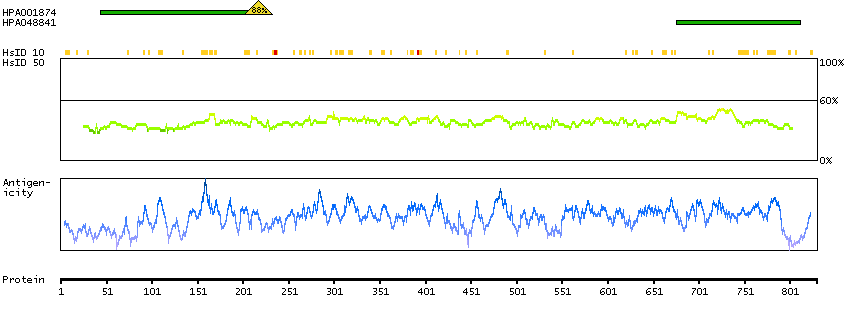
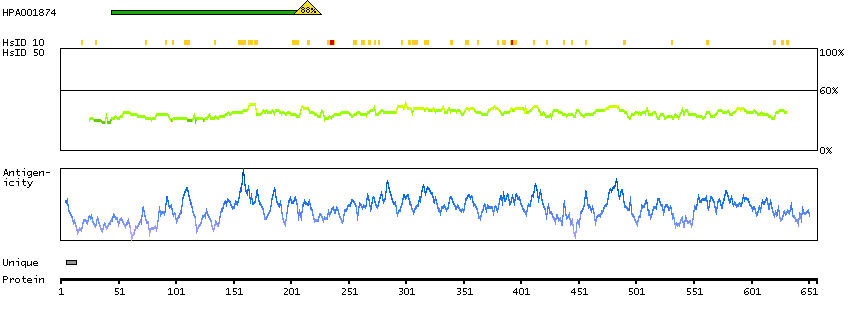
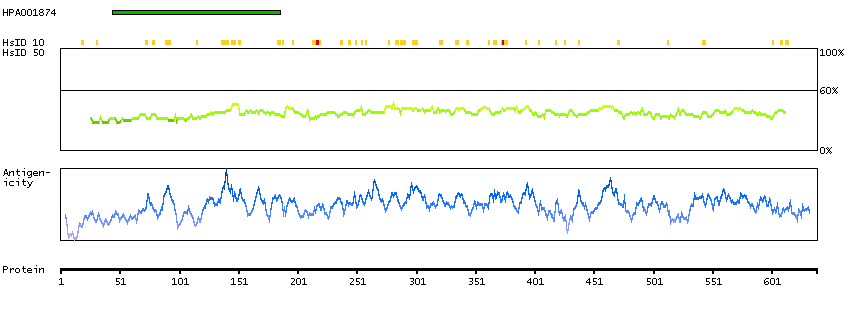
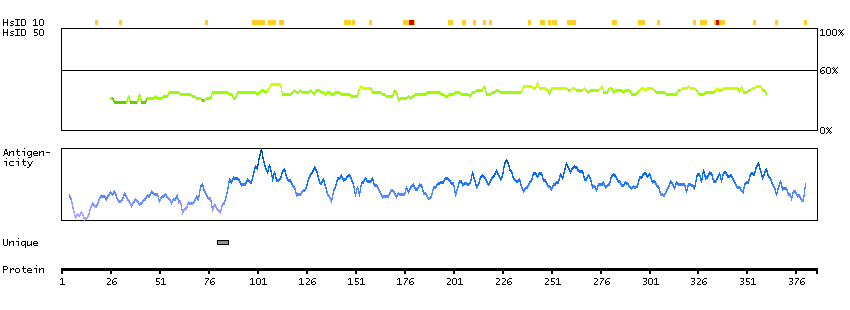
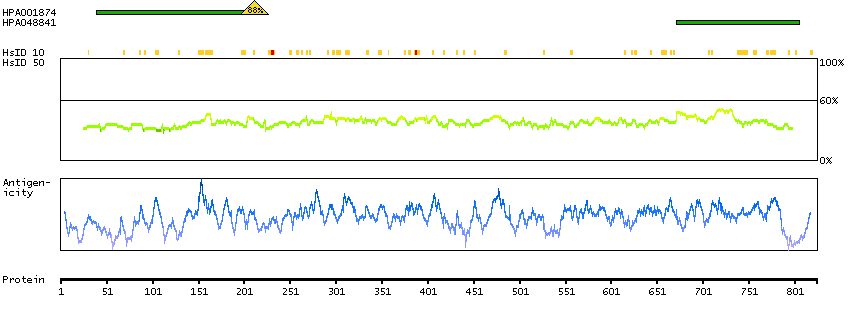
The outer dense fibers are cytoskeletal structures that surround the axoneme in the middle piece and principal piece of the sperm tail. The fibers function in maintaining the elastic structure and recoil of the sperm tail as well as in protecting the tail from shear forces during epididymal transport and ejaculation. Defects in the outer dense fibers lead to abnormal sperm morphology and infertility. This gene encodes one of the major outer dense fiber proteins. Alternative splicing results in multiple transcript variants. The longer transcripts, also known as 'Cenexins', encode proteins with a C-terminal extension that are differentially targeted to somatic centrioles and thought to be crucial for the formation of microtubule organizing centers. [provided by RefSeq, Oct 2010]