We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
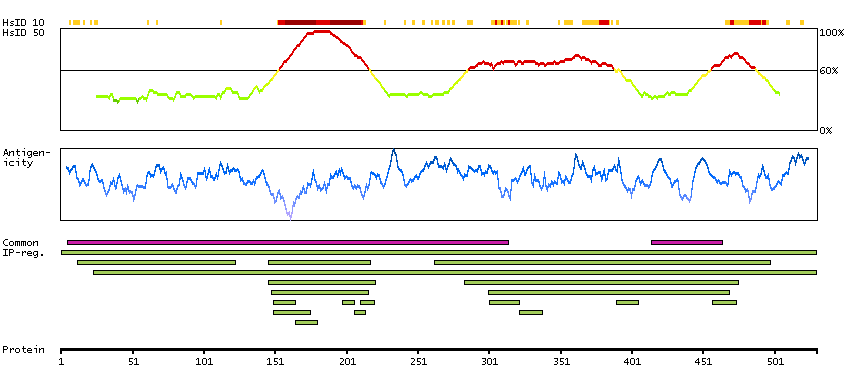
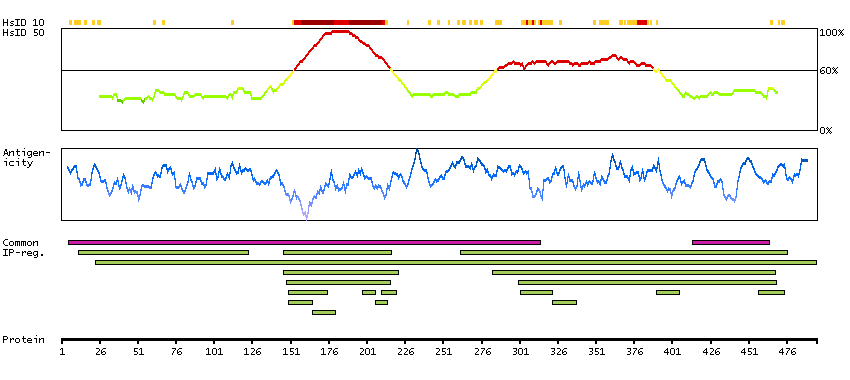
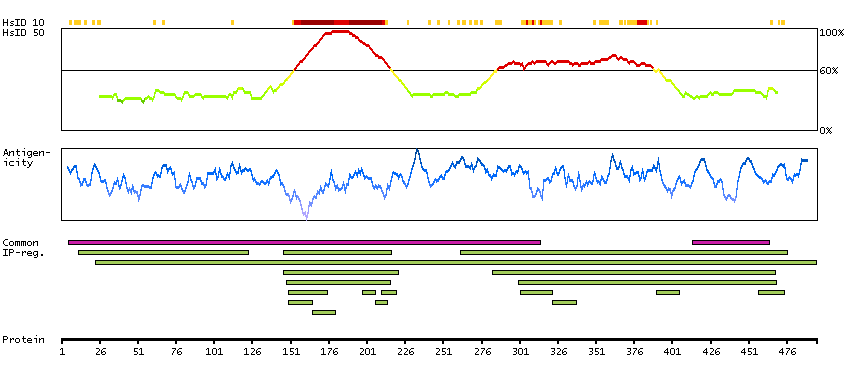
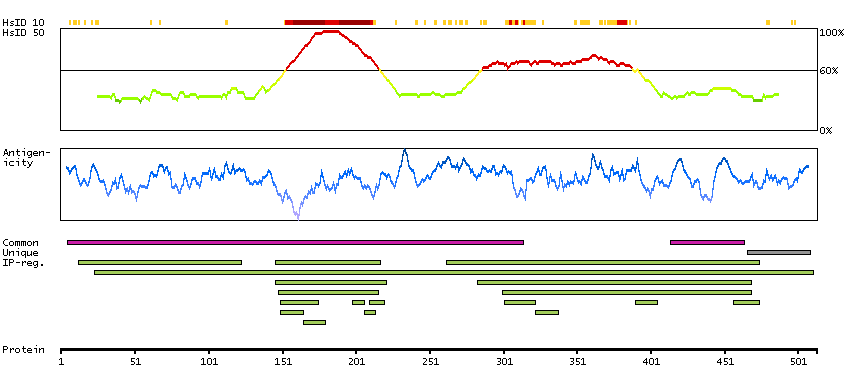
This gene encodes a member of the family of estrogen receptors and superfamily of nuclear receptor transcription factors. The gene product contains an N-terminal DNA binding domain and C-terminal ligand binding domain and is localized to the nucleus, cytoplasm, and mitochondria. Upon binding to 17beta-estradiol or related ligands, the encoded protein forms homo- or hetero-dimers that interact with specific DNA sequences to activate transcription. Some isoforms dominantly inhibit the activity of other estrogen receptor family members. Several alternatively spliced transcript variants of this gene have been described, but the full-length nature of some of these variants has not been fully characterized. [provided by RefSeq, Jul 2008]