We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
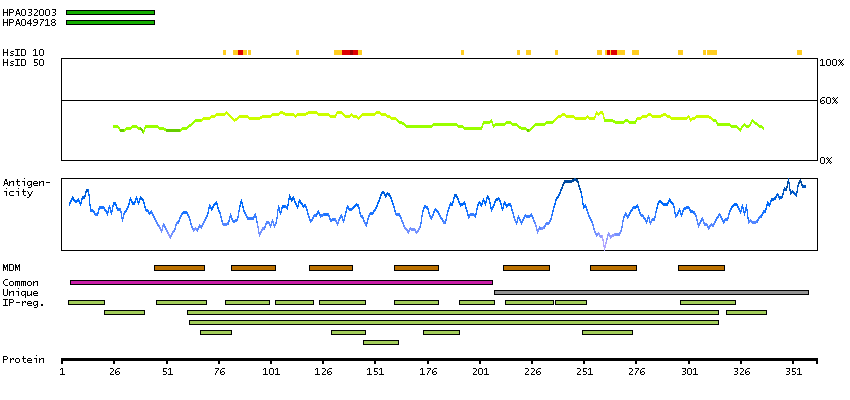
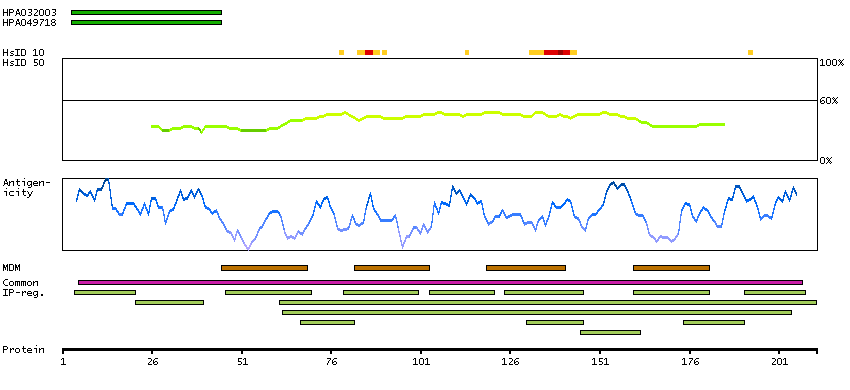
This gene encodes a member of the G-protein coupled receptor family. Although this protein was earlier thought to be a receptor for vasoactive intestinal peptide (VIP), it is now considered to be an orphan receptor, in that its endogenous ligand has not been identified. The protein is also a coreceptor for human immunodeficiency viruses (HIV). Translocations involving this gene and HMGA2 on chromosome 12 have been observed in lipomas. [provided by RefSeq, Jul 2008]