We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
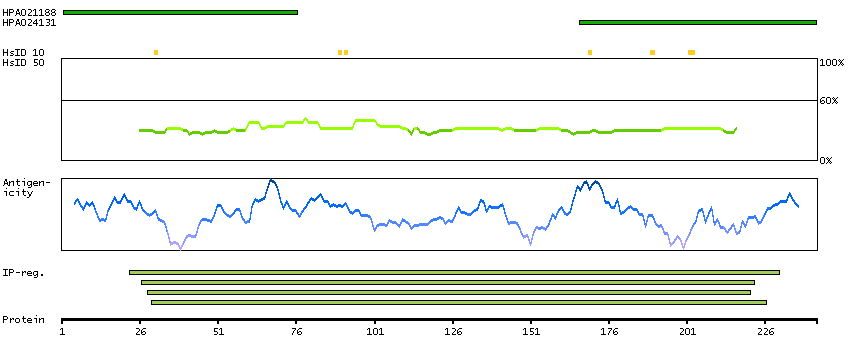
APIP is an APAF1 (MIM 602233)-interacting protein that acts as a negative regulator of ischemic/hypoxic injury (Cho et al., 2004 [PubMed 15262985]).[supplied by OMIM, Dec 2008]