We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
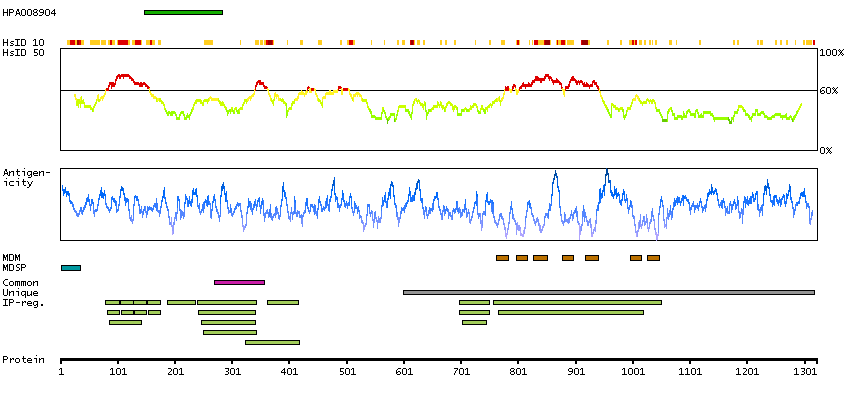
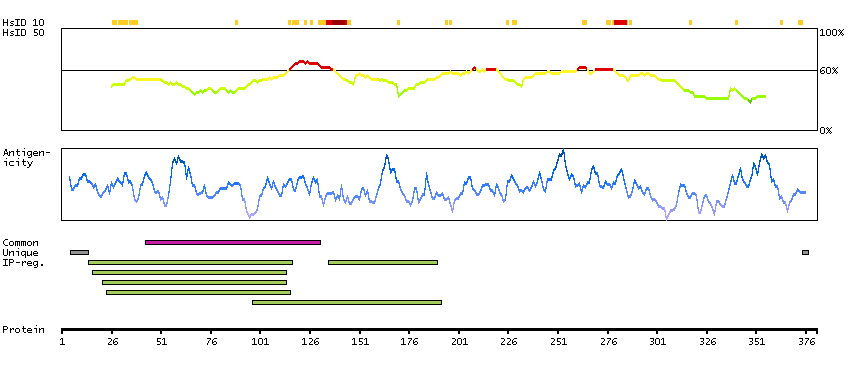
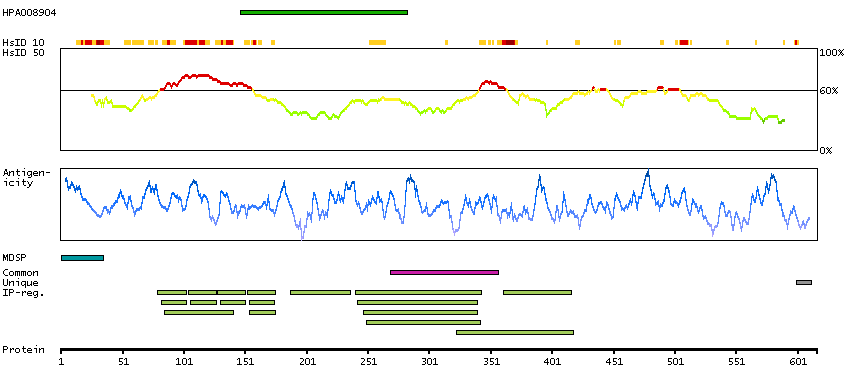
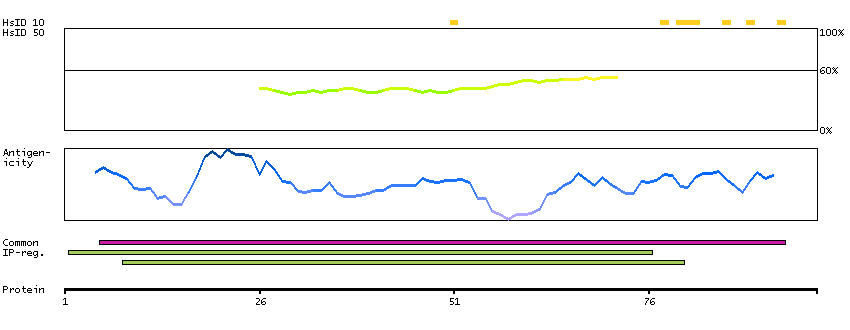
Adhesion G protein-coupled receptor A3 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the G protein-coupled receptor superfamily. This membrane protein may play a role in tumor angiogenesis through its interaction with the human homolog of the Drosophila disc large tumor suppressor gene. This gene is mapped to a candidate region of chromosome 4 which may be associated with bipolar disorder and schizophrenia. [provided by RefSeq, Oct 2012]
Q8IWK6 [Direct mapping] Adhesion G protein-coupled receptor A3
Show all
G-protein coupled receptors GPCRs excl olfactory receptors Family 2 (B) receptors Predicted intracellular proteins Protein evidence (Ezkurdia et al 2014)