We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
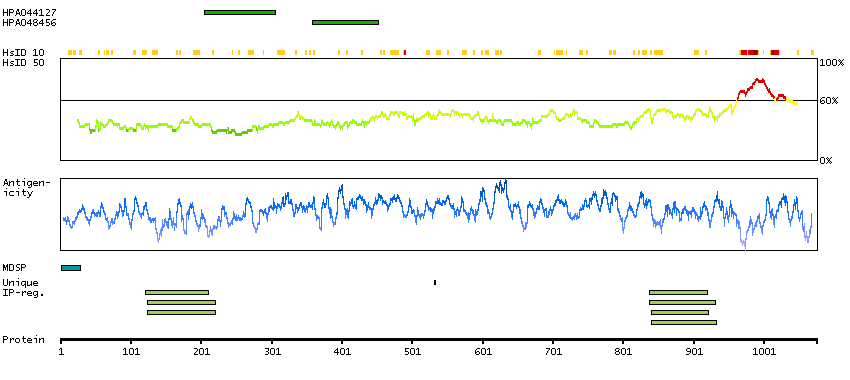
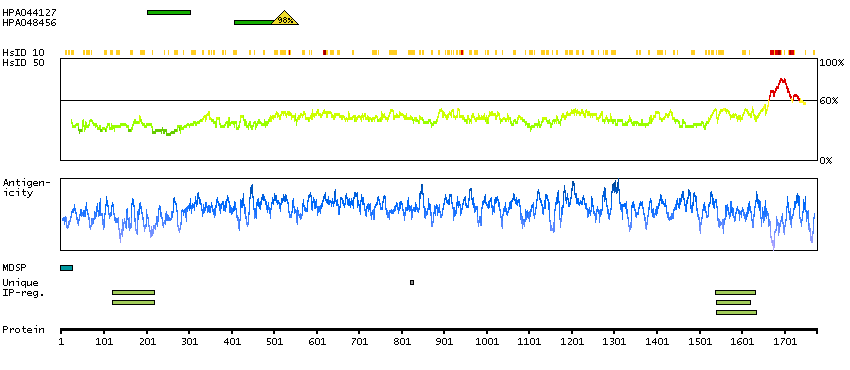
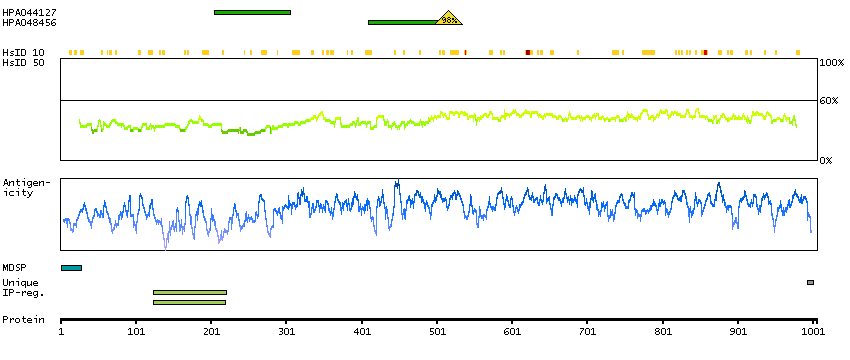
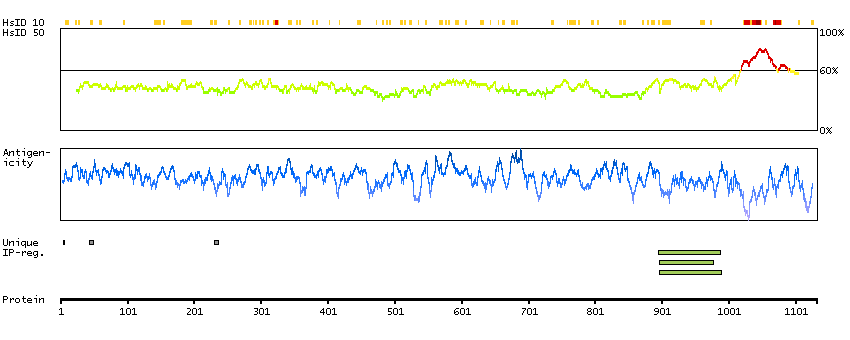
Q5JPC9 [Direct mapping] ABI gene family, member 3 (NESH) binding protein, isoform CRA_d; Putative uncharacterized protein DKFZp667H216; Target of Nesh-SH3
Show all
TMHMM predicted membrane proteins Predicted secreted proteins Secreted proteins predicted by MDSEC SignalP predicted secreted proteins Phobius predicted secreted proteins SPOCTOPUS predicted secreted proteins Protein evidence (Ezkurdia et al 2014)