We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
ATP-binding cassette, sub-family A (ABC1), member 5 (HGNC Symbol)
Entrez gene summary
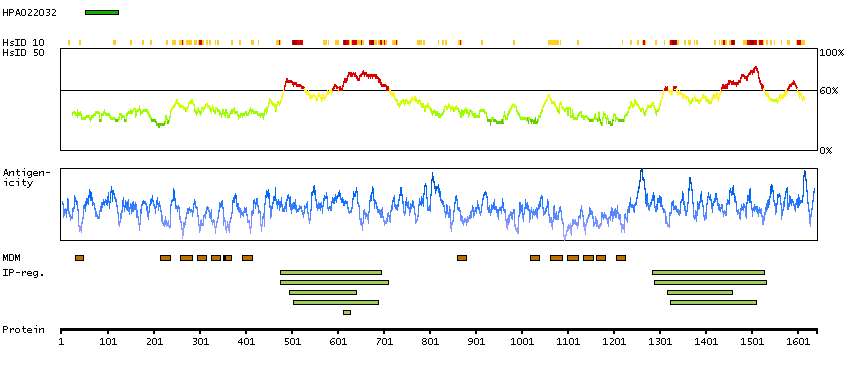
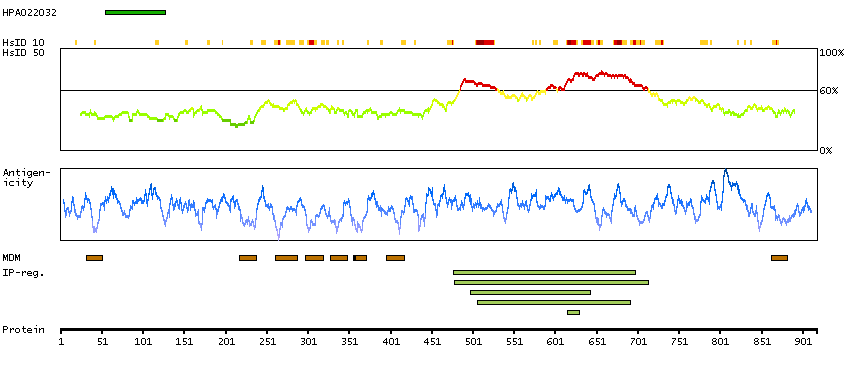
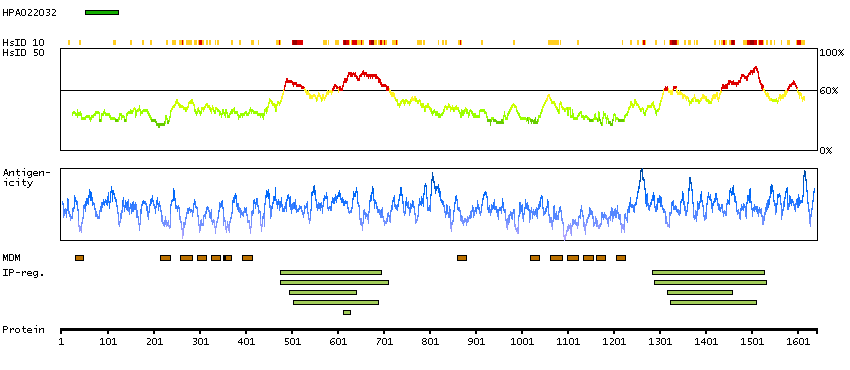
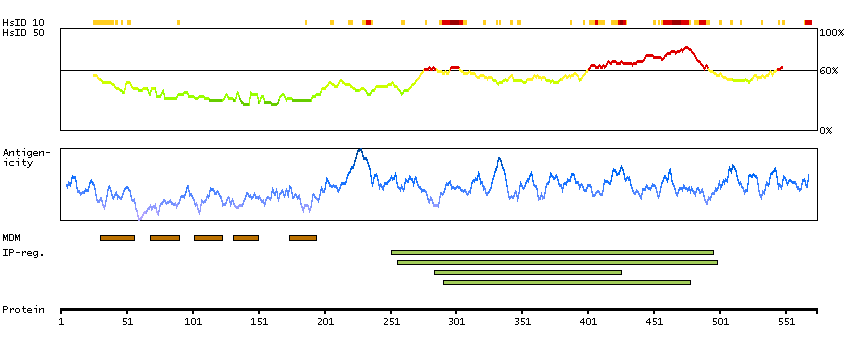
The membrane-associated protein encoded by this gene is a member of the superfamily of ATP-binding cassette (ABC) transporters. ABC proteins transport various molecules across extra- and intracellular membranes. ABC genes are divided into seven distinct subfamilies (ABC1, MDR/TAP, MRP, ALD, OABP, GCN20, and White). This encoded protein is a member of the ABC1 subfamily. Members of the ABC1 subfamily comprise the only major ABC subfamily found exclusively in multicellular eukaryotes. This gene is clustered among 4 other ABC1 family members on 17q24, but neither the substrate nor the function of this gene is known. Alternative splicing of this gene results in several transcript variants; however, not all variants have been fully described. [provided by RefSeq, Jul 2008]