We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
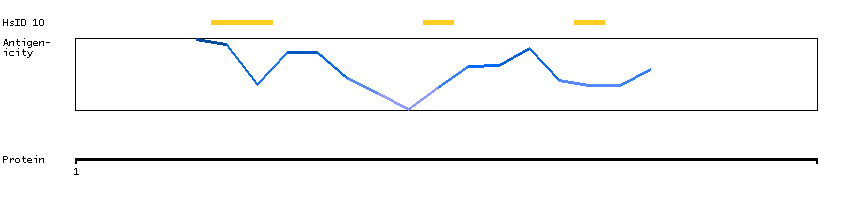
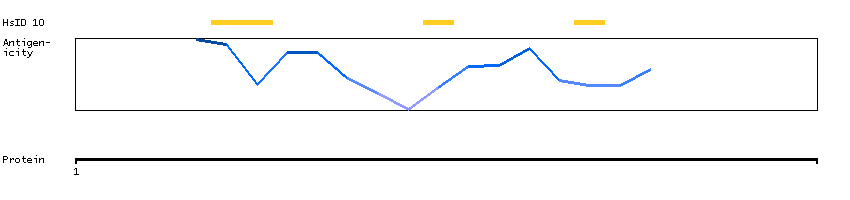
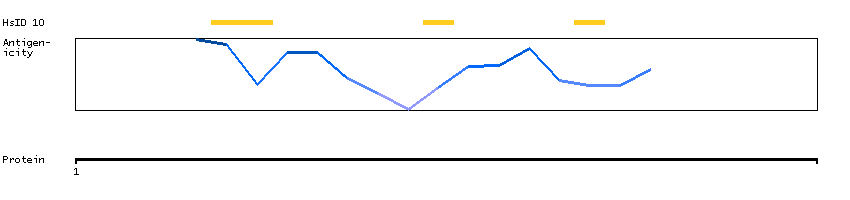
This gene encodes a transcription factor that belongs to the cap'n'collar type of basic region leucine zipper factor family (CNC-bZip). The encoded protein contains broad complex, tramtrack, bric-a-brac/poxvirus and zinc finger (BTB/POZ) domains, which is atypical of CNC-bZip family members. These BTB/POZ domains facilitate protein-protein interactions and formation of homo- and/or hetero-oligomers. When this encoded protein forms a heterodimer with MafK, it functions as a repressor of Maf recognition element (MARE) and transcription is repressed. Multiple alternatively spliced transcript variants have been identified for this gene. [provided by RefSeq, May 2009]
O14867 [Direct mapping] Transcription regulator protein BACH1
Show all
Predicted intracellular proteins Plasma proteins Transcription factors Basic domains Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000083 [regulation of transcription involved in G1/S transition of mitotic cell cycle] GO:0000117 [regulation of transcription involved in G2/M transition of mitotic cell cycle] GO:0000122 [negative regulation of transcription from RNA polymerase II promoter] GO:0000980 [RNA polymerase II distal enhancer sequence-specific DNA binding] GO:0001078 [transcriptional repressor activity, RNA polymerase II core promoter proximal region sequence-specific binding] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0004842 [ubiquitin-protein transferase activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006281 [DNA repair] GO:0006355 [regulation of transcription, DNA-templated] GO:0016567 [protein ubiquitination] GO:0020037 [heme binding] GO:0031463 [Cul3-RING ubiquitin ligase complex] GO:0043565 [sequence-specific DNA binding] GO:0061418 [regulation of transcription from RNA polymerase II promoter in response to hypoxia]
O14867 [Direct mapping] Transcription regulator protein BACH1
Show all
Predicted intracellular proteins Plasma proteins Transcription factors Basic domains Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000083 [regulation of transcription involved in G1/S transition of mitotic cell cycle] GO:0000117 [regulation of transcription involved in G2/M transition of mitotic cell cycle] GO:0000122 [negative regulation of transcription from RNA polymerase II promoter] GO:0000980 [RNA polymerase II distal enhancer sequence-specific DNA binding] GO:0001078 [transcriptional repressor activity, RNA polymerase II core promoter proximal region sequence-specific binding] GO:0001205 [transcriptional activator activity, RNA polymerase II distal enhancer sequence-specific binding] GO:0001206 [transcriptional repressor activity, RNA polymerase II distal enhancer sequence-specific binding] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0004842 [ubiquitin-protein transferase activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006281 [DNA repair] GO:0006355 [regulation of transcription, DNA-templated] GO:0006366 [transcription from RNA polymerase II promoter] GO:0016567 [protein ubiquitination] GO:0020037 [heme binding] GO:0031463 [Cul3-RING ubiquitin ligase complex] GO:0043565 [sequence-specific DNA binding] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0061418 [regulation of transcription from RNA polymerase II promoter in response to hypoxia]