We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
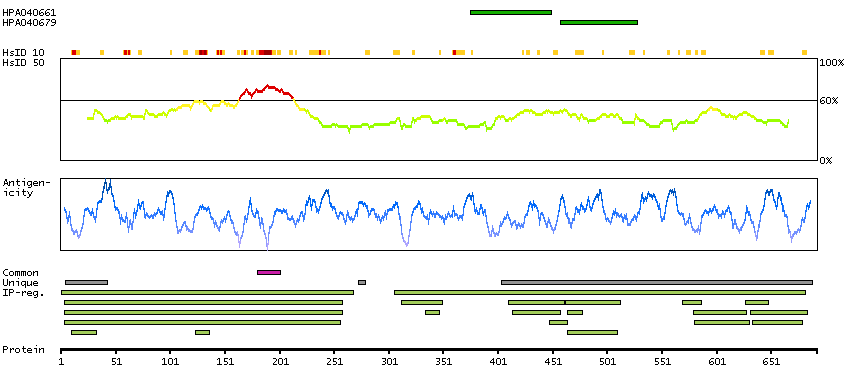
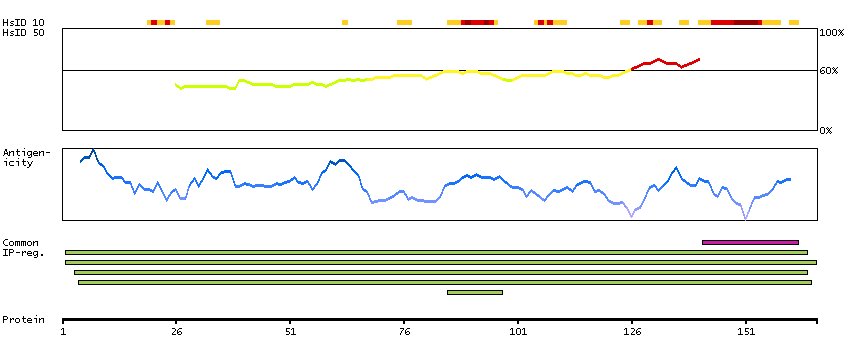
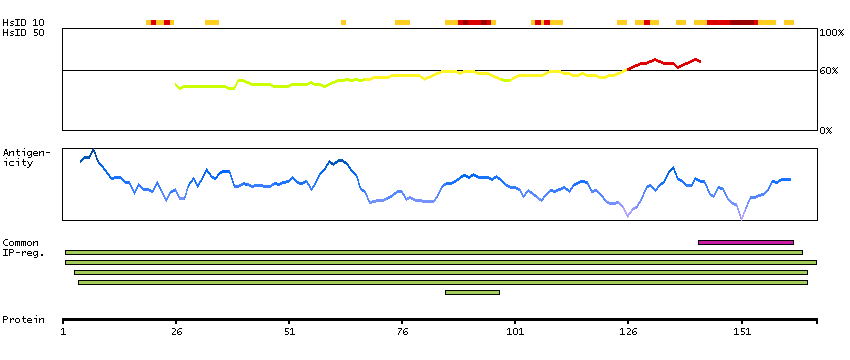
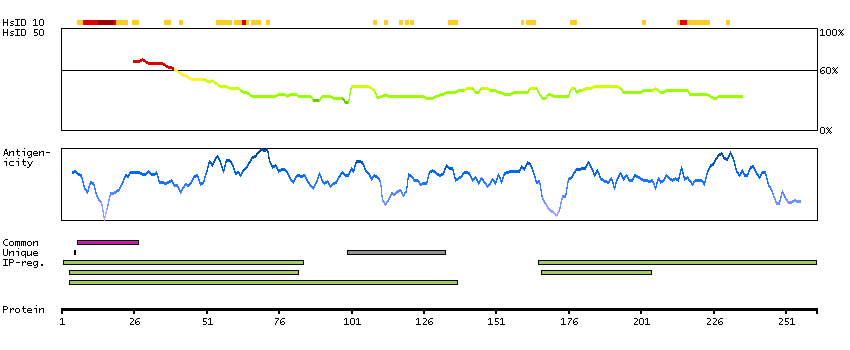
This gene encodes a member of the serine/threionine protein kinase family related to NIMA (never in mitosis, gene A) of Aspergillus nidulans. The encoded protein may play a role in cell cycle progression from G2 to M phase. Mutations in the related mouse gene are associated with a disease phenotype that closely parallels the juvenile autosomal recessive form of polycystic kidney disease in humans. [provided by RefSeq, Jul 2008]