We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Homeodomain interacting protein kinase 1 (HGNC Symbol)
Entrez gene summary
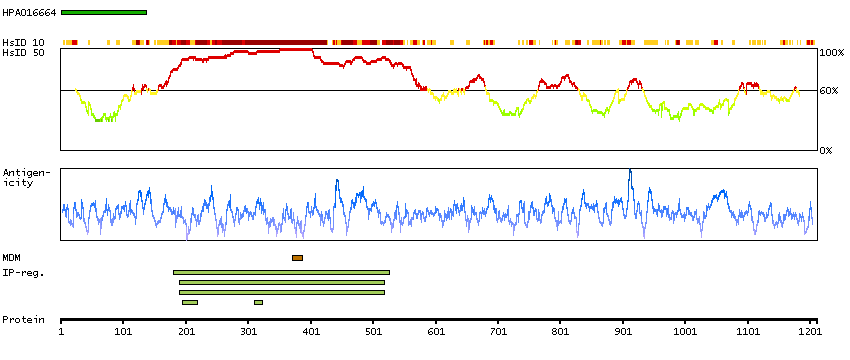
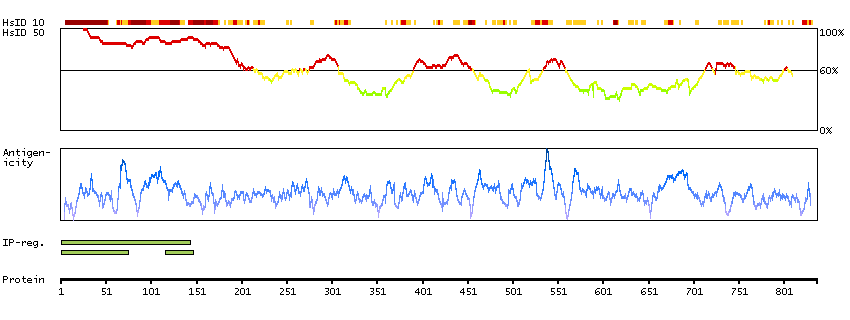
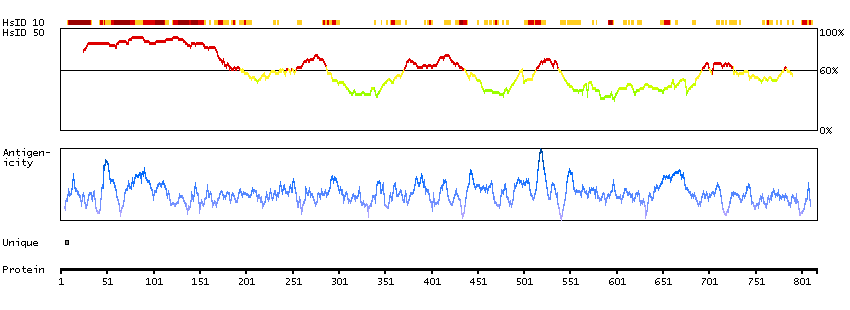
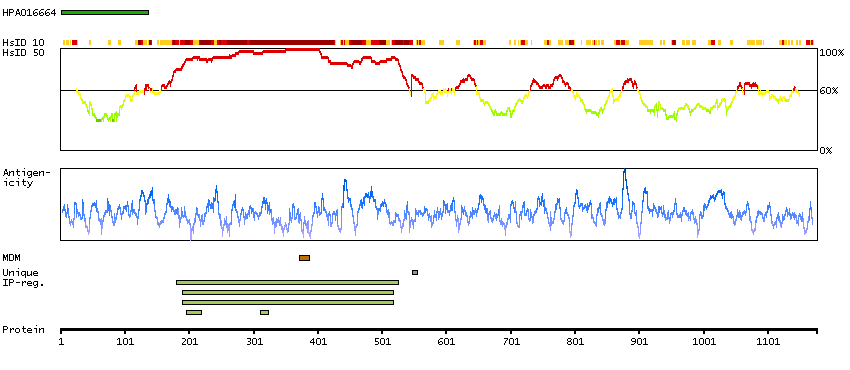
The protein encoded by this gene belongs to the Ser/Thr family of protein kinases and HIPK subfamily. It phosphorylates homeodomain transcription factors and may also function as a co-repressor for homeodomain transcription factors. Alternative splicing results in four transcript variants encoding four distinct isoforms. [provided by RefSeq, Jul 2008]
Q86Z02 [Direct mapping] Homeodomain-interacting protein kinase 1
Show all
Enzymes ENZYME proteins Transferases Kinases CMGC Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)