We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Nitric oxide is a reactive free radical which acts as a biologic mediator in several processes, including neurotransmission and antimicrobial and antitumoral activities. Nitric oxide is synthesized from L-arginine by nitric oxide synthases. Variations in this gene are associated with susceptibility to coronary spasm. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, May 2009]
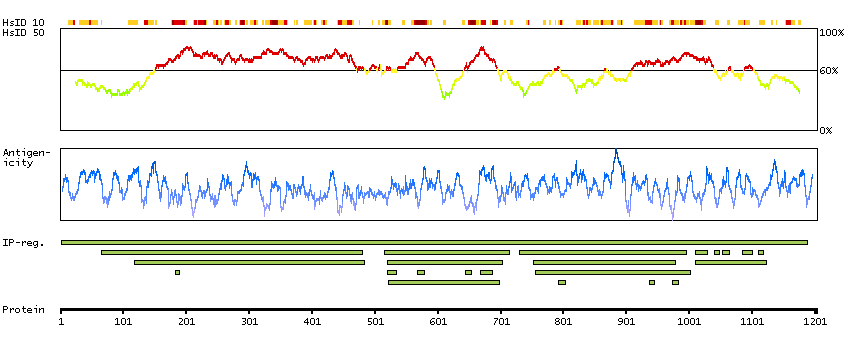
Enzymes ENZYME proteins Oxidoreductases SCAMPI predicted membrane proteins SPOCTOPUS predicted secreted proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000139 [Golgi membrane] GO:0001525 [angiogenesis] GO:0001542 [ovulation from ovarian follicle] GO:0001701 [in utero embryonic development] GO:0001974 [blood vessel remodeling] GO:0002028 [regulation of sodium ion transport] GO:0003057 [regulation of the force of heart contraction by chemical signal] GO:0003100 [regulation of systemic arterial blood pressure by endothelin] GO:0003785 [actin monomer binding] GO:0003958 [NADPH-hemoprotein reductase activity] GO:0004517 [nitric-oxide synthase activity] GO:0005506 [iron ion binding] GO:0005515 [protein binding] GO:0005516 [calmodulin binding] GO:0005634 [nucleus] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0005856 [cytoskeleton] GO:0005886 [plasma membrane] GO:0005901 [caveola] GO:0006527 [arginine catabolic process] GO:0006809 [nitric oxide biosynthetic process] GO:0007005 [mitochondrion organization] GO:0007263 [nitric oxide mediated signal transduction] GO:0007596 [blood coagulation] GO:0008217 [regulation of blood pressure] GO:0008285 [negative regulation of cell proliferation] GO:0009408 [response to heat] GO:0010181 [FMN binding] GO:0010544 [negative regulation of platelet activation] GO:0014740 [negative regulation of muscle hyperplasia] GO:0014806 [smooth muscle hyperplasia] GO:0016491 [oxidoreductase activity] GO:0019430 [removal of superoxide radicals] GO:0020037 [heme binding] GO:0030324 [lung development] GO:0030666 [endocytic vesicle membrane] GO:0031284 [positive regulation of guanylate cyclase activity] GO:0031663 [lipopolysaccharide-mediated signaling pathway] GO:0034405 [response to fluid shear stress] GO:0034617 [tetrahydrobiopterin binding] GO:0034618 [arginine binding] GO:0043267 [negative regulation of potassium ion transport] GO:0043542 [endothelial cell migration] GO:0044281 [small molecule metabolic process] GO:0045766 [positive regulation of angiogenesis] GO:0045776 [negative regulation of blood pressure] GO:0045909 [positive regulation of vasodilation] GO:0046209 [nitric oxide metabolic process] GO:0046870 [cadmium ion binding] GO:0048010 [vascular endothelial growth factor receptor signaling pathway] GO:0050660 [flavin adenine dinucleotide binding] GO:0050661 [NADP binding] GO:0050880 [regulation of blood vessel size] GO:0050999 [regulation of nitric-oxide synthase activity] GO:0051346 [negative regulation of hydrolase activity] GO:0051926 [negative regulation of calcium ion transport] GO:0055114 [oxidation-reduction process] GO:0090382 [phagosome maturation] GO:0097110 [scaffold protein binding] GO:1902042 [negative regulation of extrinsic apoptotic signaling pathway via death domain receptors]
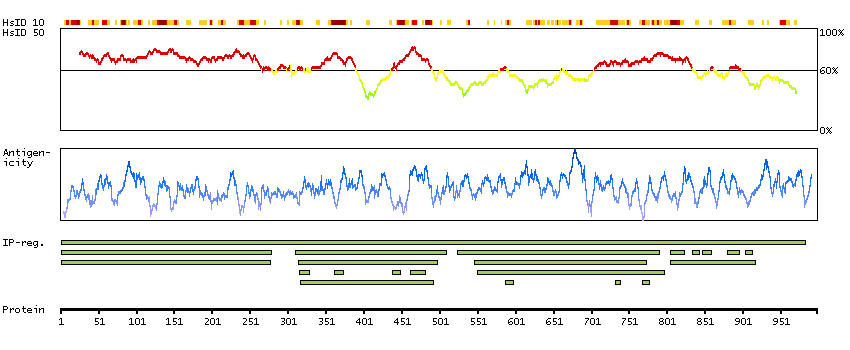
Enzymes ENZYME proteins Oxidoreductases SPOCTOPUS predicted secreted proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)