We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
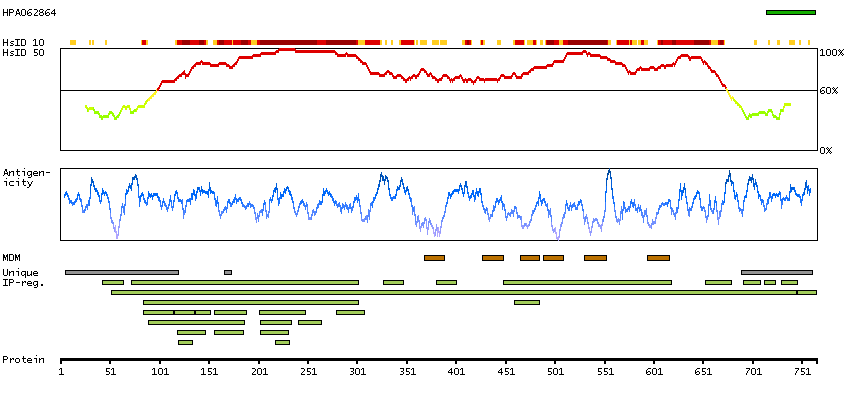
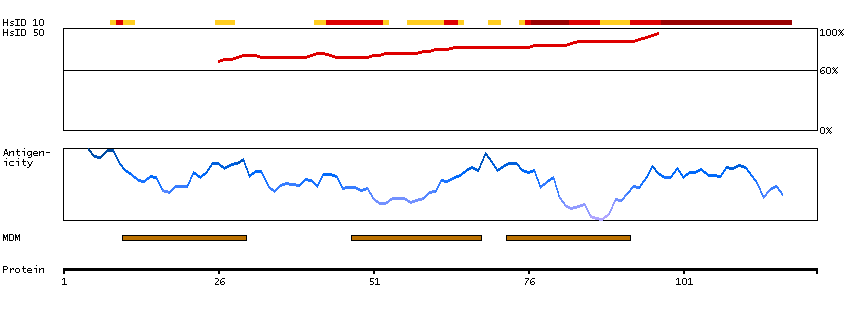
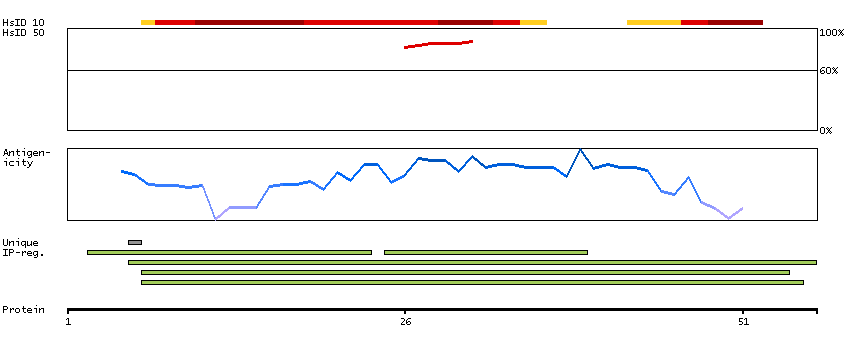
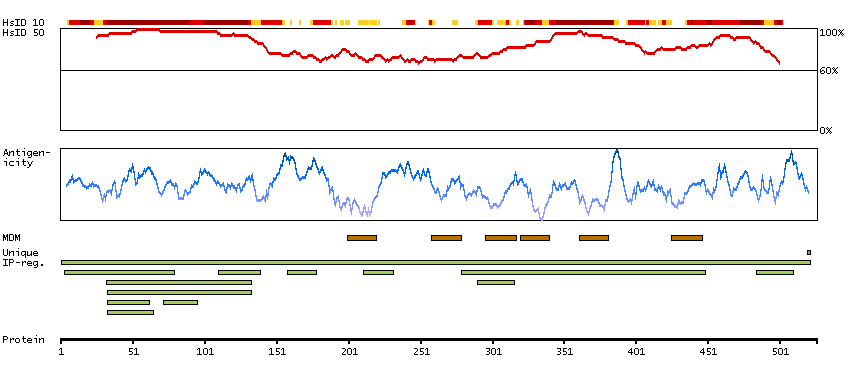
This gene encodes a member of a family of multipass membrane proteins that functions as calcium channels. The encoded protein contains N-terminal ankyrin repeats, which are required for channel assembly and regulation. Translation initiation for this protein occurs at a non-AUG start codon that is decoded as methionine. This gene is situated next to a closely related gene for transient receptor potential cation channel subfamily V member 5 (TRPV5). This locus has experienced positive selection in non-African populations, resulting in several non-synonymous codon differences among individuals of different genetic backgrounds. [provided by RefSeq, Feb 2015]