We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
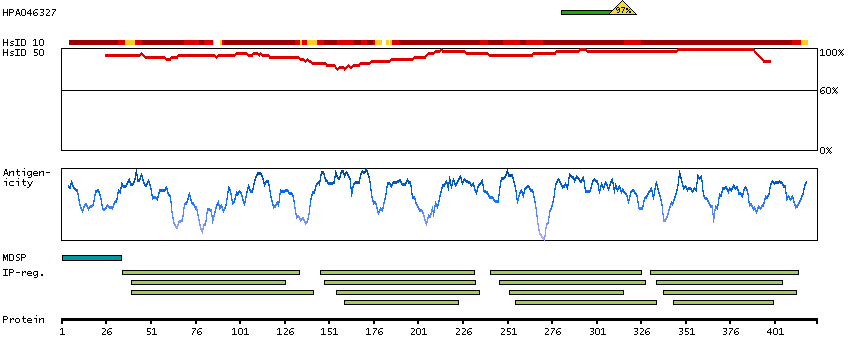
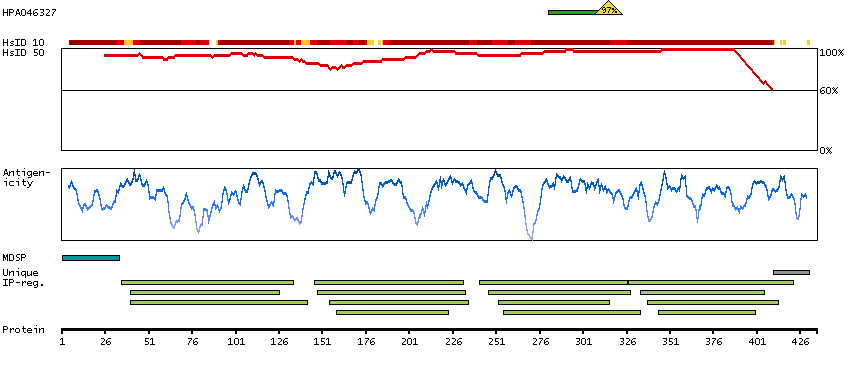
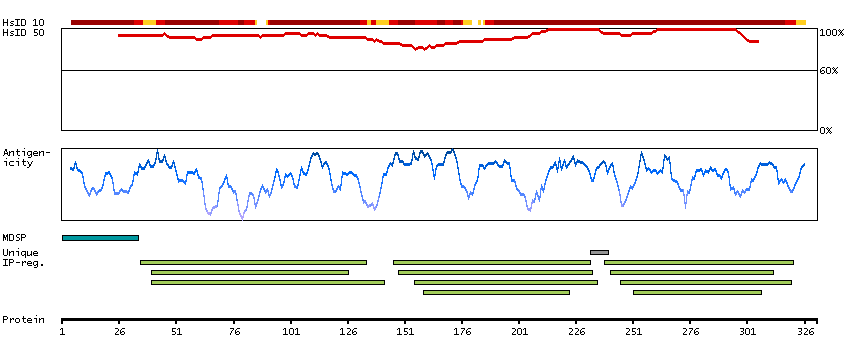
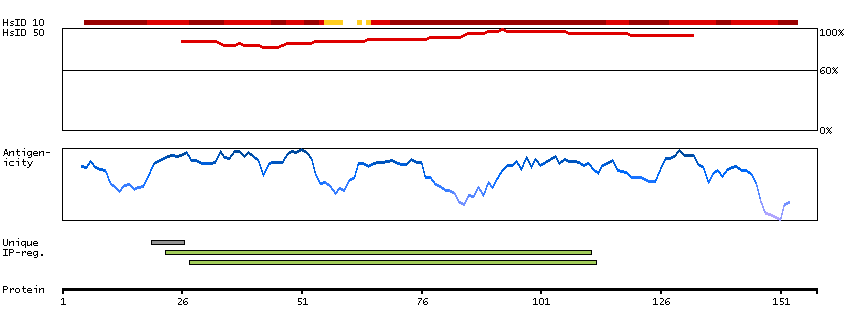
Antibody staining mainly not consistent with RNA expression data. Caution, targets protein from more than one gene. Presumed off target binding observed and disregarded.
Pregnancy specific beta-1-glycoprotein 6 (HGNC Symbol)
Entrez gene summary
This gene is a member of the pregnancy-specific glycoprotein (PSG) gene family. The PSG genes are a subgroup of the carcinoembryonic antigen (CEA) family of immunoglobulin-like genes, and are found in a gene cluster at 19q13.1-q13.2 telomeric to another cluster of CEA-related genes. The PSG genes are expressed by placental trophoblasts and released into the maternal circulation during pregnancy, and are thought to be essential for maintenance of normal pregnancy. The protein encoded by this gene contains the Arg-Gly-Asp tripeptide associated with cellular adhesion and recognition. Alternative splicing results in multiple transcript variants and protein isoforms. [provided by RefSeq, Jul 2012]