We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
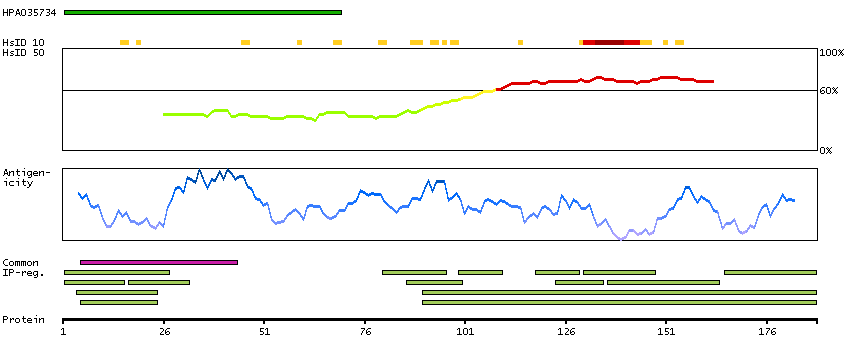
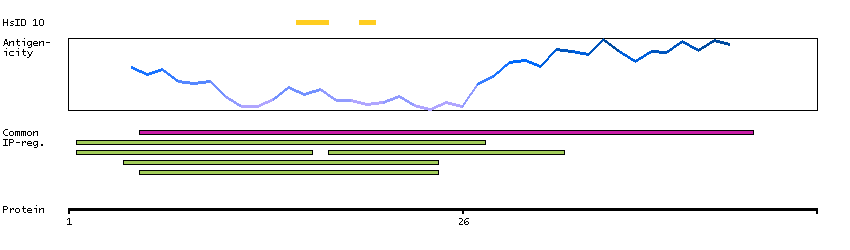
The protein encoded by this gene belongs to the BCL-2 protein family. BCL-2 family members form hetero- or homodimers and act as anti- or pro-apoptotic regulators that are involved in a wide variety of cellular activities. The proteins encoded by this gene are located at the outer mitochondrial membrane, and have been shown to regulate outer mitochondrial membrane channel (VDAC) opening. VDAC regulates mitochondrial membrane potential, and thus controls the production of reactive oxygen species and release of cytochrome C by mitochondria, both of which are the potent inducers of cell apoptosis. Two alternatively spliced transcript variants, which encode distinct isoforms, have been reported. The longer isoform acts as an apoptotic inhibitor and the shorter form acts as an apoptotic activator. [provided by RefSeq, Jul 2008]