We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
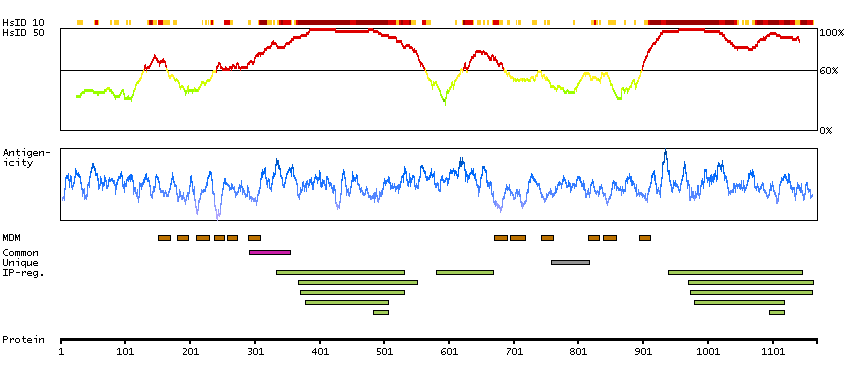
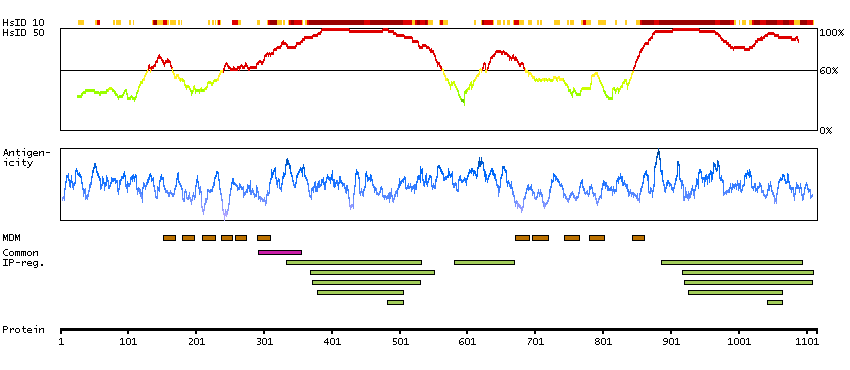
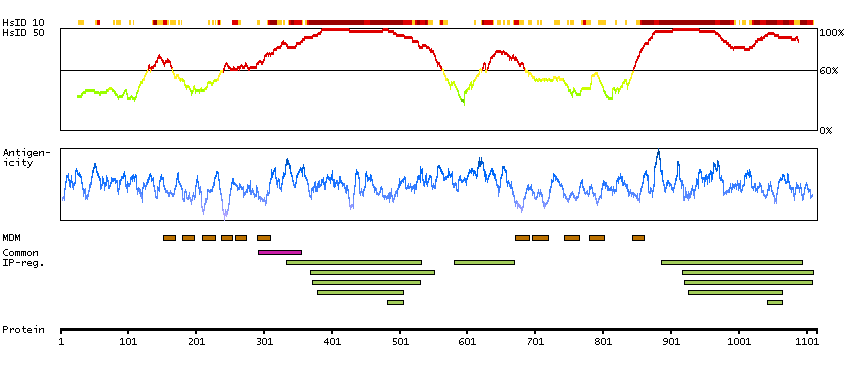
This gene encodes a member of the adenylyl cyclase family of proteins, which are required for the synthesis of cyclic AMP. All members of this family have an intracellular N-terminus, a tandem repeat of six transmembrane domains separated by a cytoplasmic loop, and a C-terminal cytoplasmic domain. The two cytoplasmic regions bind ATP and form the catalytic core of the protein. Adenylyl cyclases are important effectors of transmembrane signaling pathways and are regulated by the activity of G protein coupled receptor signaling. This protein belongs to a small subclass of adenylyl cyclase proteins that are functionally related and are inhibited by protein kinase A, calcium ions and nitric oxide. A mutation in this gene is associated with arthrogryposis multiplex congenita. [provided by RefSeq, May 2015]