We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
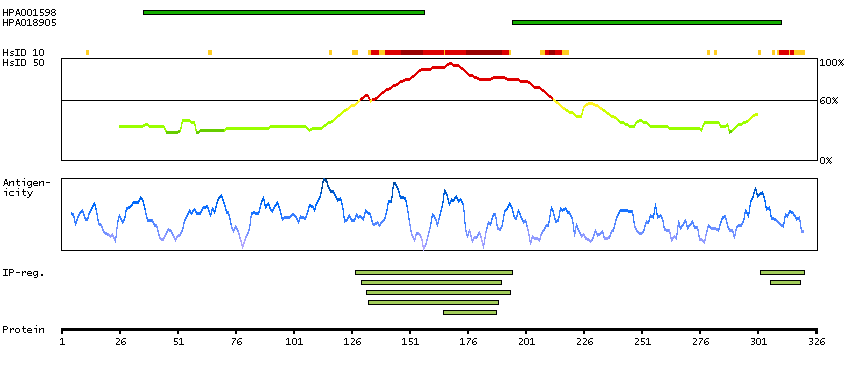
The specific function of this gene has yet to be determined in humans; however, in rodents, it is necessary for survival of the forebrain mesenchyme and may also be involved in development of the cervix. Mutations in the mouse gene lead to neural tube defects such as acrania and meroanencephaly. [provided by RefSeq, Jul 2008]