We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
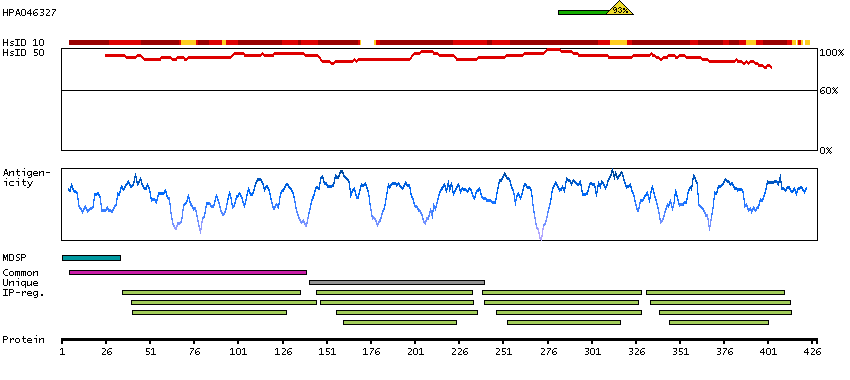
Antibody staining mainly not consistent with RNA expression data. Caution, targets protein from more than one gene. Presumed off target binding observed and disregarded.
Pregnancy specific beta-1-glycoprotein 5 (HGNC Symbol)
Entrez gene summary
The human pregnancy-specific glycoproteins (PSGs) are a group of molecules that are mainly produced by the placental syncytiotrophoblasts during pregnancy. PSGs comprise a subgroup of the carcinoembryonic antigen (CEA) family, which belongs to the immunoglobulin superfamily. For additional general information about the PSG gene family, see PSG1 (MIM 176390).[supplied by OMIM, Oct 2009]
Predicted secreted proteins Secreted proteins predicted by MDSEC SignalP predicted secreted proteins SPOCTOPUS predicted secreted proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)