We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
AT rich interactive domain 1B (SWI1-like) (HGNC Symbol)
Entrez gene summary
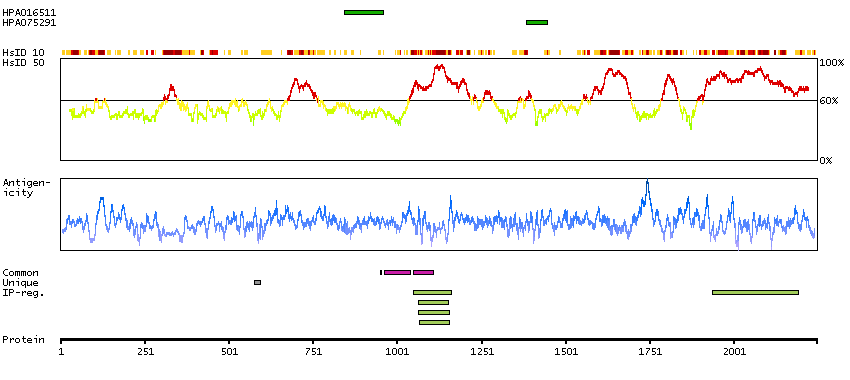
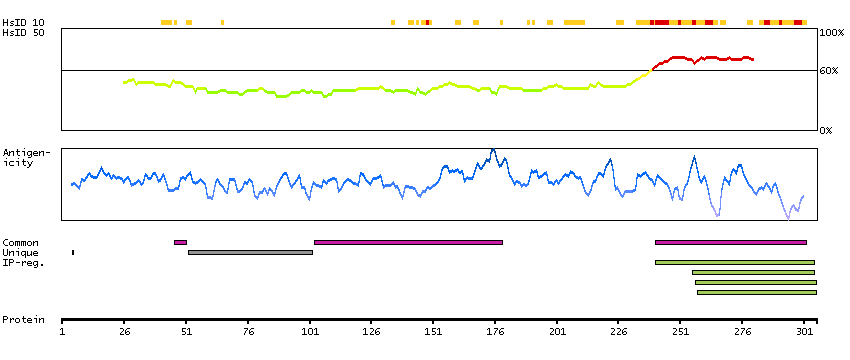
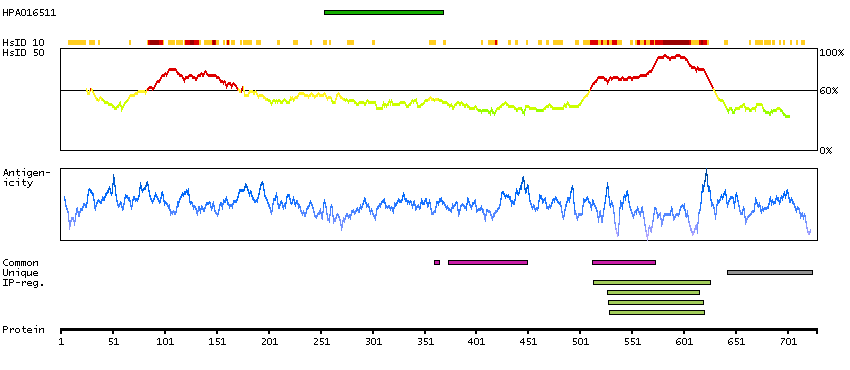
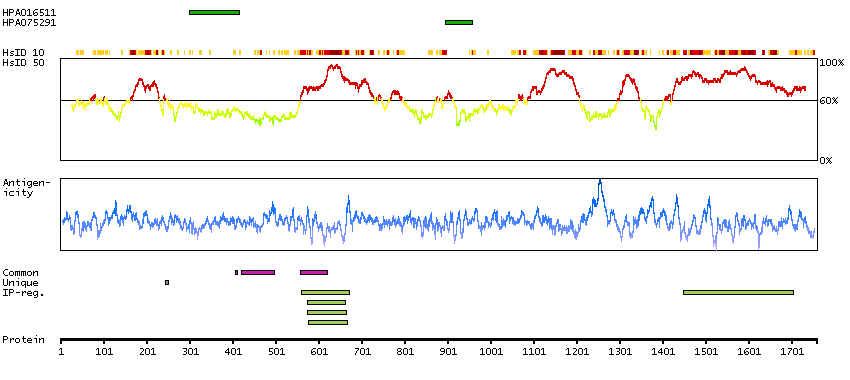
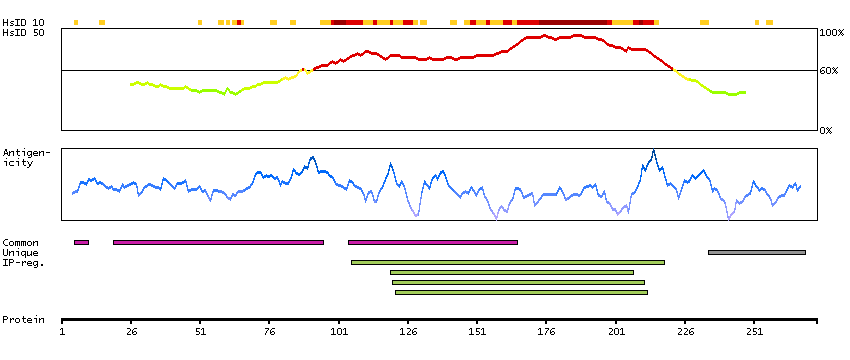
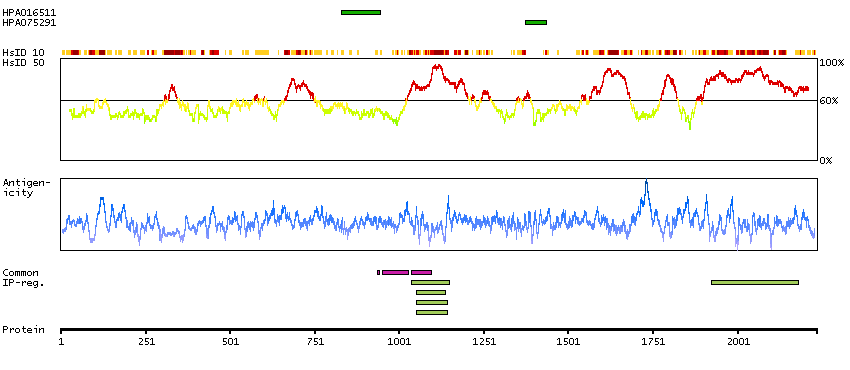
This locus encodes an AT-rich DNA interacting domain-containing protein. The encoded protein is a component of the SWI/SNF chromatin remodeling complex and may play a role in cell-cycle activation. The protein encoded by this locus is similar to AT-rich interactive domain-containing protein 1A. These two proteins function as alternative, mutually exclusive ARID-subunits of the SWI/SNF complex. The associated complexes play opposing roles. Alternatively spliced transcript variants encoding different isoforms have been described. [provided by RefSeq, Feb 2012]
Q8NFD5 [Direct mapping] AT-rich interactive domain-containing protein 1B
Show all
THUMBUP predicted membrane proteins Predicted intracellular proteins Transcription factors Helix-turn-helix domains Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Other Mutations COSMIC Nonsense Mutations COSMIC Missense Mutations COSMIC Frameshift Mutations Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)