We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
The protein encoded by this gene belongs to the highly conserved cyclin family, whose members are characterized by a dramatic periodicity in protein abundance through the cell cycle. Cyclins function as regulators of CDK kinases. Different cyclins exhibit distinct expression and degradation patterns which contribute to the temporal coordination of each mitotic event. This cyclin forms a complex with and functions as a regulatory subunit of CDK2, whose activity is required for cell cycle G1/S transition. This protein accumulates at the G1-S phase boundary and is degraded as cells progress through S phase. Overexpression of this gene has been observed in many tumors, which results in chromosome instability, and thus may contribute to tumorigenesis. This protein was found to associate with, and be involved in, the phosphorylation of NPAT protein (nuclear protein mapped to the ATM locus), which participates in cell-cycle regulated histone gene expression and plays a critical role in promoting cell-cycle progression in the absence of pRB. Two alternatively spliced transcript variants of this gene, which encode distinct isoforms, have been described. Two additional splice variants were reported but detailed nucleotide sequence information is not yet available. [provided by RefSeq, Jul 2008]
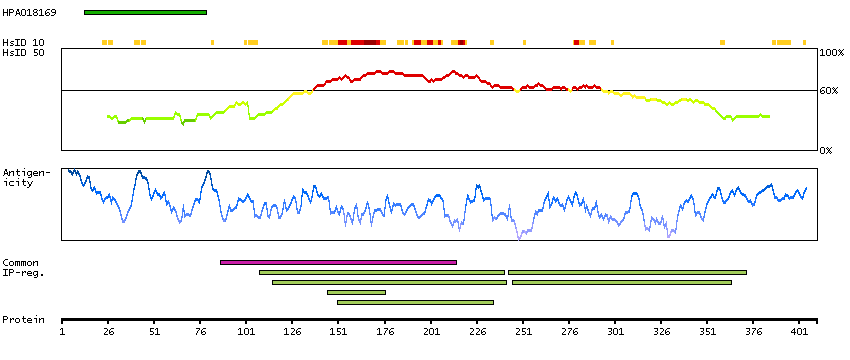
THUMBUP predicted membrane proteins Predicted intracellular proteins Cancer-related genes Candidate cancer biomarkers COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000082 [G1/S transition of mitotic cell cycle] GO:0000083 [regulation of transcription involved in G1/S transition of mitotic cell cycle] GO:0000278 [mitotic cell cycle] GO:0000307 [cyclin-dependent protein kinase holoenzyme complex] GO:0001547 [antral ovarian follicle growth] GO:0001889 [liver development] GO:0003713 [transcription coactivator activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005813 [centrosome] GO:0005829 [cytosol] GO:0006270 [DNA replication initiation] GO:0006468 [protein phosphorylation] GO:0010243 [response to organonitrogen compound] GO:0014070 [response to organic cyclic compound] GO:0014074 [response to purine-containing compound] GO:0016055 [Wnt signaling pathway] GO:0016301 [kinase activity] GO:0016538 [cyclin-dependent protein serine/threonine kinase regulator activity] GO:0019901 [protein kinase binding] GO:0030521 [androgen receptor signaling pathway] GO:0031100 [organ regeneration] GO:0031670 [cellular response to nutrient] GO:0032355 [response to estradiol] GO:0032403 [protein complex binding] GO:0032570 [response to progesterone] GO:0033197 [response to vitamin E] GO:0034097 [response to cytokine] GO:0042493 [response to drug] GO:0045471 [response to ethanol] GO:0045597 [positive regulation of cell differentiation] GO:0045859 [regulation of protein kinase activity] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0048545 [response to steroid hormone] GO:0050681 [androgen receptor binding] GO:0051301 [cell division] GO:0051412 [response to corticosterone] GO:0051597 [response to methylmercury] GO:0051726 [regulation of cell cycle]
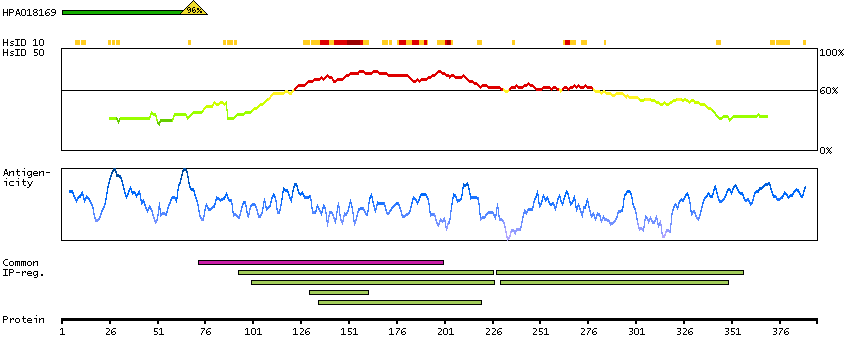
THUMBUP predicted membrane proteins Predicted intracellular proteins Cancer-related genes Candidate cancer biomarkers COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations Protein evidence (Ezkurdia et al 2014)
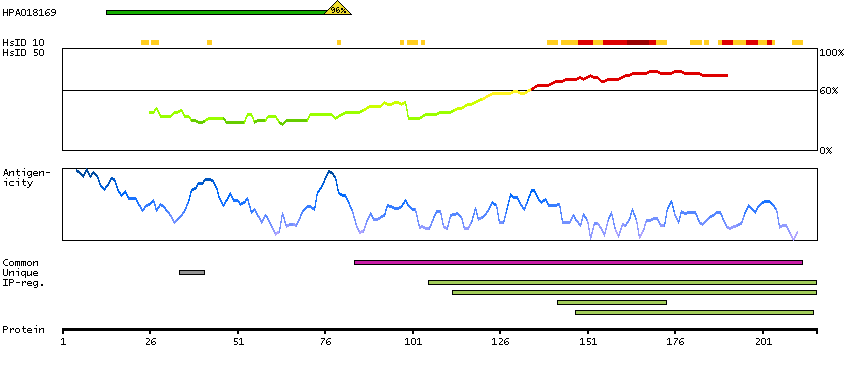
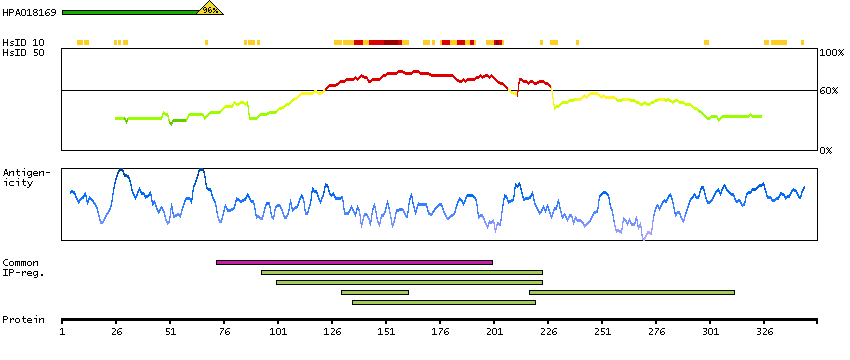
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Amplifications COSMIC Somatic Mutations Protein evidence (Ezkurdia et al 2014)