We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
ATP-binding cassette, sub-family C (CFTR/MRP), member 5 (HGNC Symbol)
Entrez gene summary
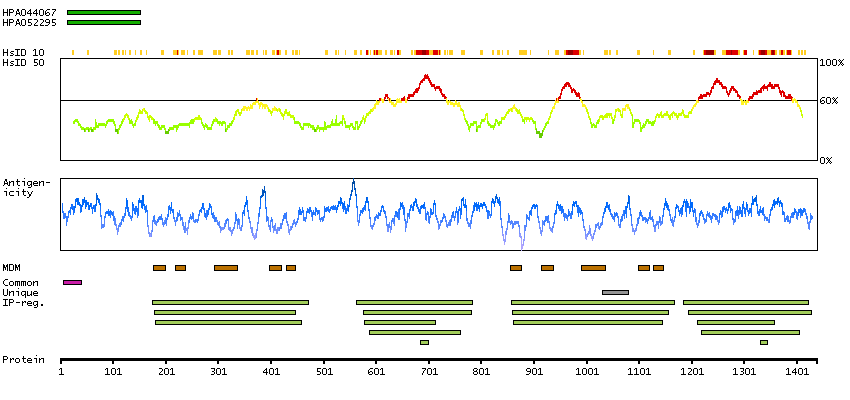
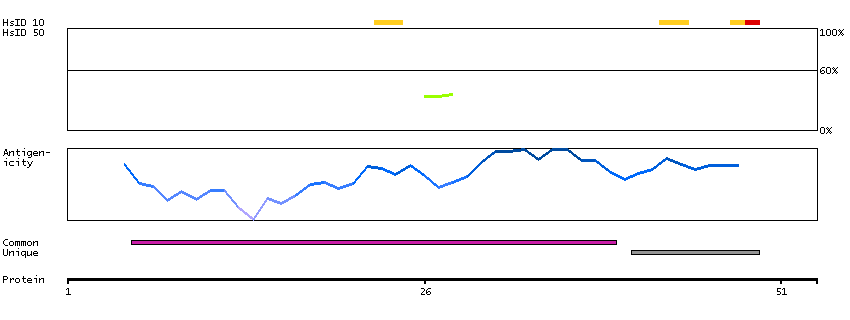
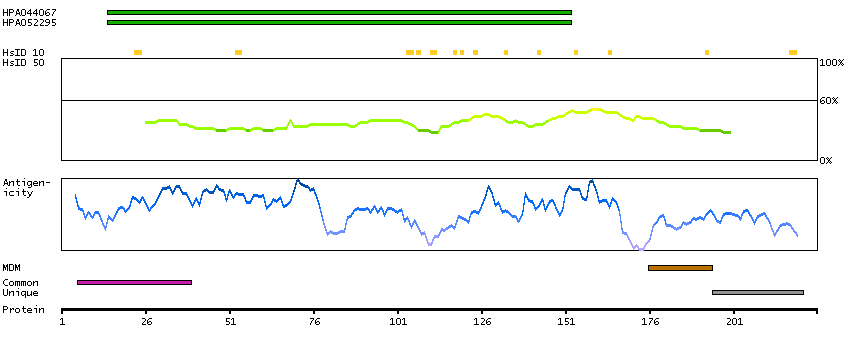
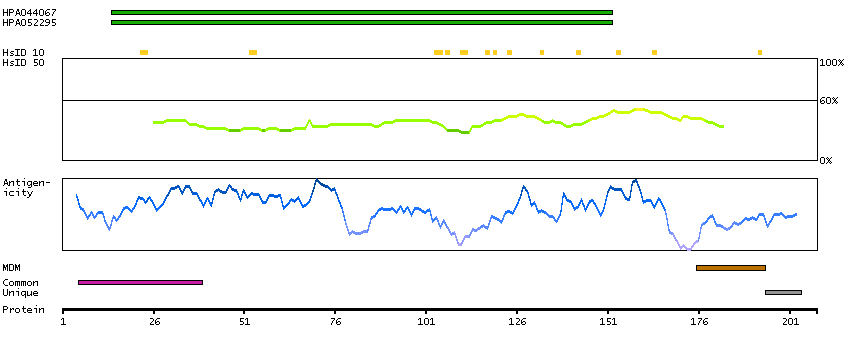
The protein encoded by this gene is a member of the superfamily of ATP-binding cassette (ABC) transporters. ABC proteins transport various molecules across extra- and intra-cellular membranes. ABC genes are divided into seven distinct subfamilies (ABC1, MDR/TAP, MRP, ALD, OABP, GCN20, White). This protein is a member of the MRP subfamily which is involved in multi-drug resistance. This protein functions in the cellular export of its substrate, cyclic nucleotides. This export contributes to the degradation of phosphodiesterases and possibly an elimination pathway for cyclic nucleotides. Studies show that this protein provides resistance to thiopurine anticancer drugs, 6-mercatopurine and thioguanine, and the anti-HIV drug 9-(2-phosphonylmethoxyethyl)adenine. This protein may be involved in resistance to thiopurines in acute lymphoblastic leukemia and antiretroviral nucleoside analogs in HIV-infected patients. Alternative splicing of this gene has been detected; however, the complete sequence and translation initiation site is unclear. [provided by RefSeq, Jul 2008]