We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
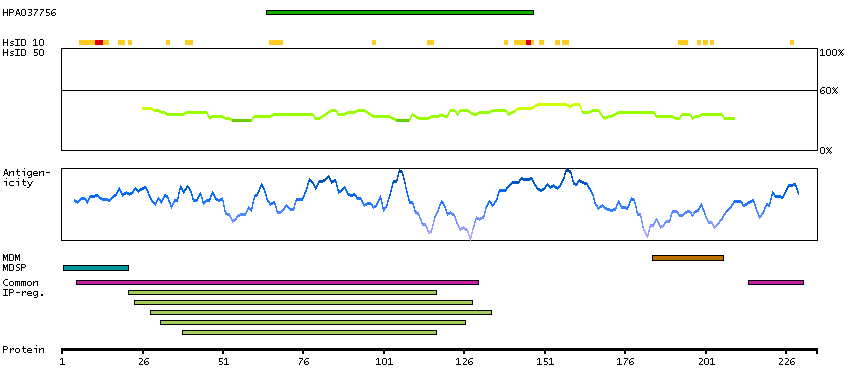
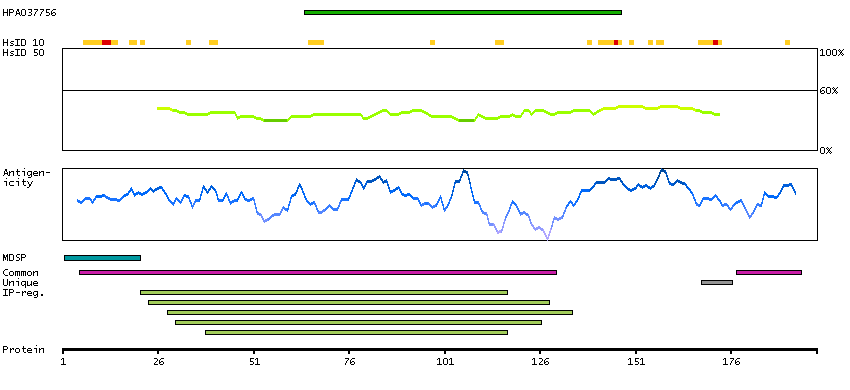
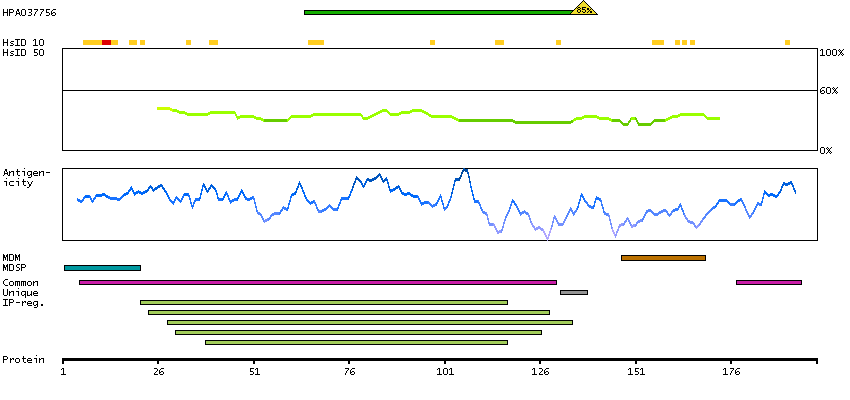
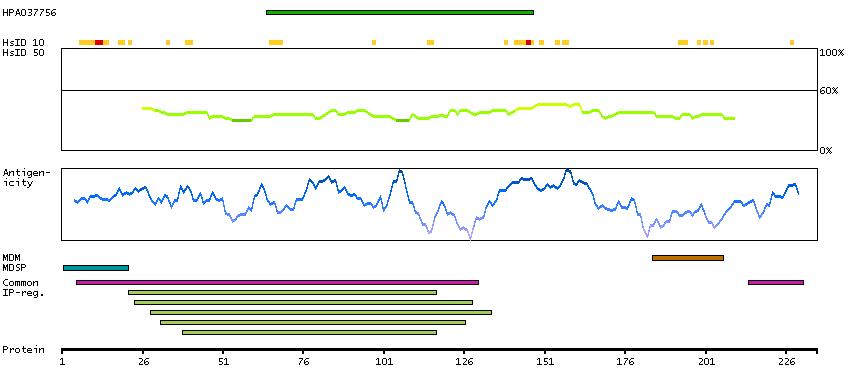
The CD8 antigen is a cell surface glycoprotein found on most cytotoxic T lymphocytes that mediates efficient cell-cell interactions within the immune system. The CD8 antigen acts as a coreceptor with the T-cell receptor on the T lymphocyte to recognize antigens displayed by an antigen presenting cell in the context of class I MHC molecules. The coreceptor functions as either a homodimer composed of two alpha chains or as a heterodimer composed of one alpha and one beta chain. Both alpha and beta chains share significant homology to immunoglobulin variable light chains. This gene encodes the CD8 alpha chain. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Nov 2011]
CD markers Predicted secreted proteins Secreted proteins predicted by MDSEC SignalP predicted secreted proteins Phobius predicted secreted proteins SPOCTOPUS predicted secreted proteins Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0002456 [T cell mediated immunity] GO:0005515 [protein binding] GO:0005576 [extracellular region] GO:0005886 [plasma membrane] GO:0005887 [integral component of plasma membrane] GO:0006955 [immune response] GO:0007166 [cell surface receptor signaling pathway] GO:0007169 [transmembrane receptor protein tyrosine kinase signaling pathway] GO:0009897 [external side of plasma membrane] GO:0015026 [coreceptor activity] GO:0019882 [antigen processing and presentation] GO:0042101 [T cell receptor complex] GO:0042110 [T cell activation] GO:0042288 [MHC class I protein binding] GO:0045065 [cytotoxic T cell differentiation] GO:0050776 [regulation of immune response]