We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Calcium channel, voltage-dependent, T type, alpha 1H subunit (HGNC Symbol)
Entrez gene summary
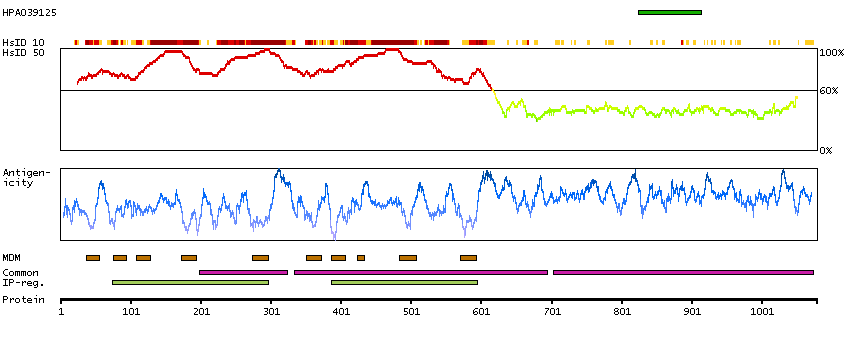
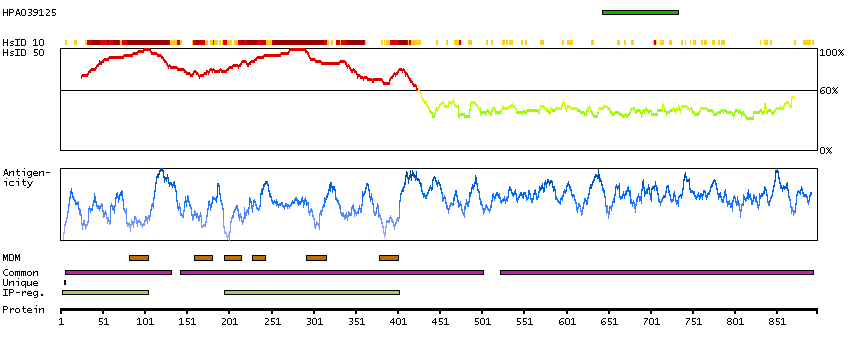
This gene encodes a T-type member of the alpha-1 subunit family, a protein in the voltage-dependent calcium channel complex. Calcium channels mediate the influx of calcium ions into the cell upon membrane polarization and consist of a complex of alpha-1, alpha-2/delta, beta, and gamma subunits in a 1:1:1:1 ratio. The alpha-1 subunit has 24 transmembrane segments and forms the pore through which ions pass into the cell. There are multiple isoforms of each of the proteins in the complex, either encoded by different genes or the result of alternative splicing of transcripts. Alternate transcriptional splice variants, encoding different isoforms, have been characterized for the gene described here. Studies suggest certain mutations in this gene lead to childhood absence epilepsy (CAE). [provided by RefSeq, Jul 2008]