We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Mitogen-activated protein kinase kinase kinase MLT (UniProtKB/Swiss-Prot)
Entrez gene summary
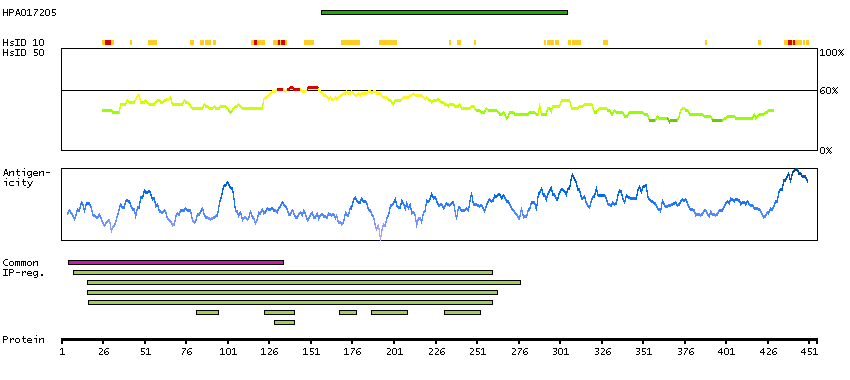
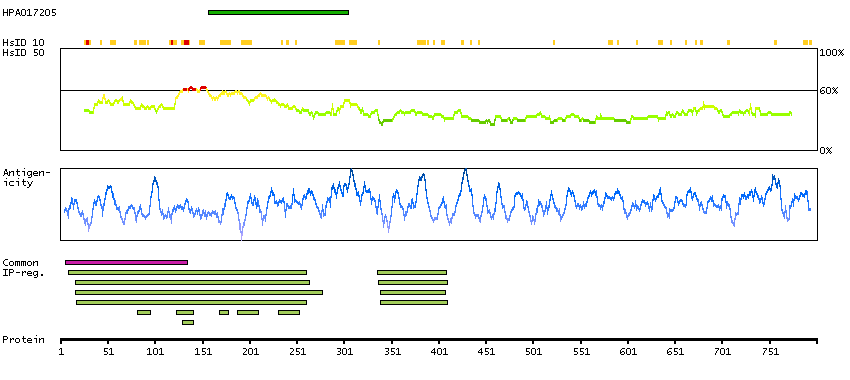
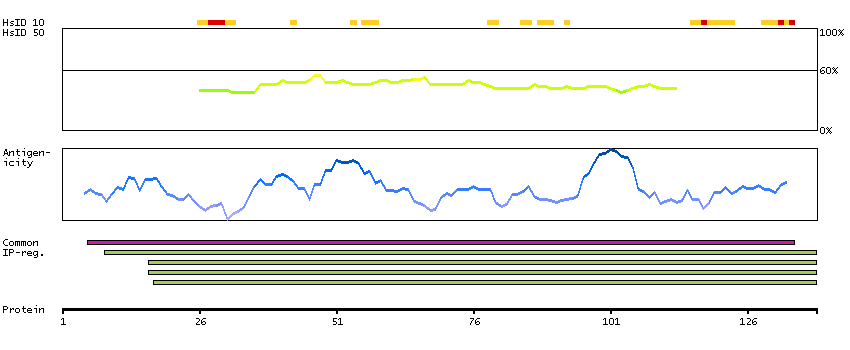
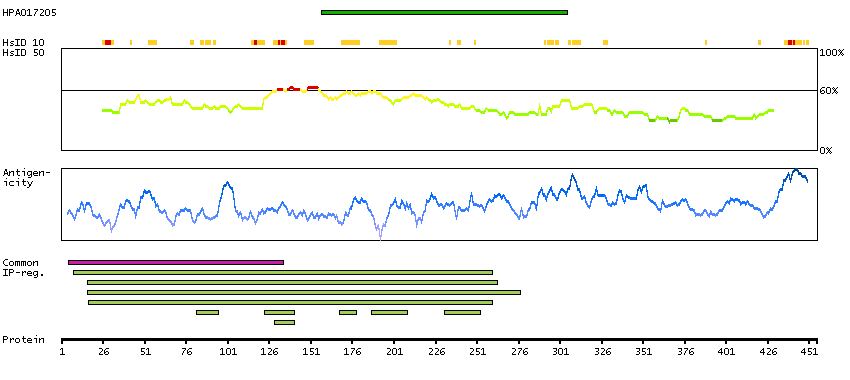
This gene is a member of the MAPKKK family of signal transduction molecules and encodes a protein with an N-terminal kinase catalytic domain, followed by a leucine zipper motif and a sterile-alpha motif (SAM). This magnesium-binding protein forms homodimers and is located in the cytoplasm. The protein mediates gamma radiation signaling leading to cell cycle arrest and activity of this protein plays a role in cell cycle checkpoint regulation in cells. The protein also has pro-apoptotic activity. Alternate transcriptional splice variants, encoding different isoforms, have been characterized. [provided by RefSeq, Jul 2008]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)