We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
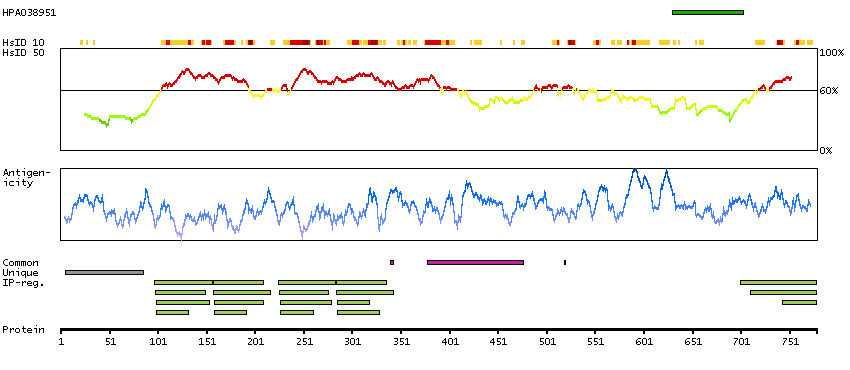
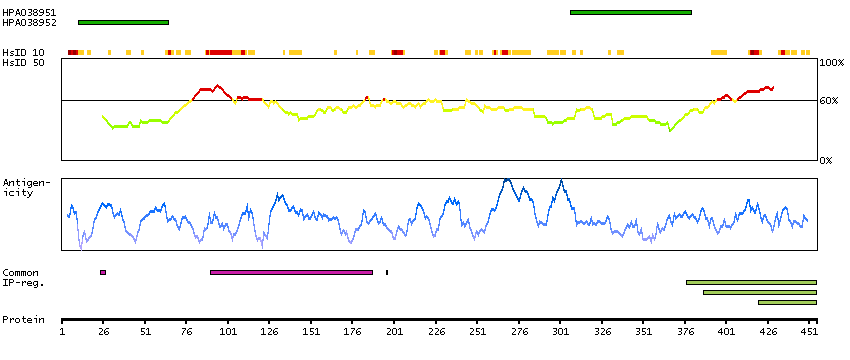
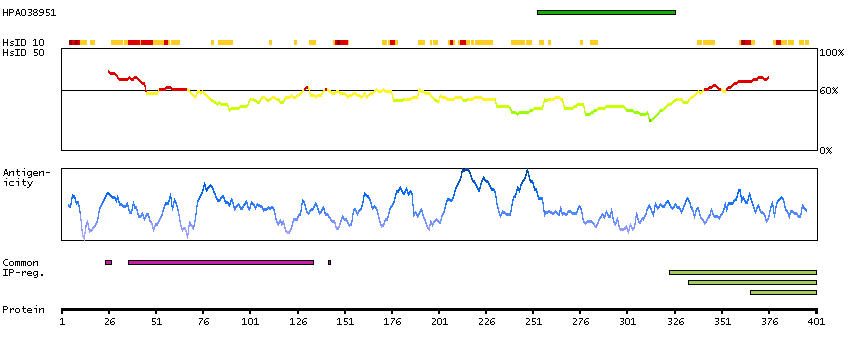
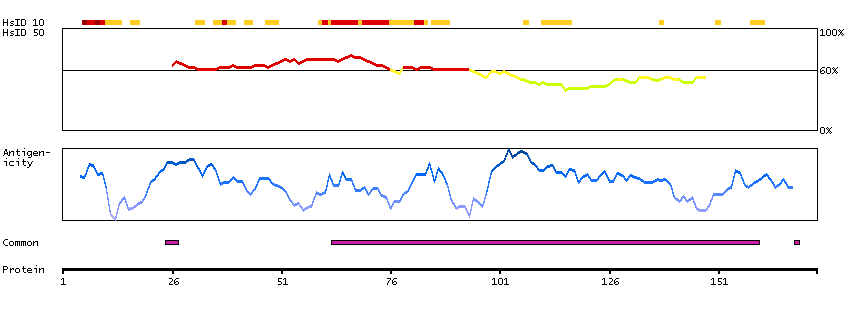
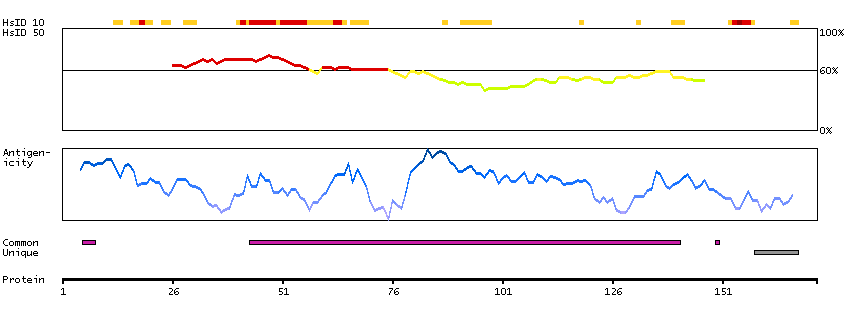
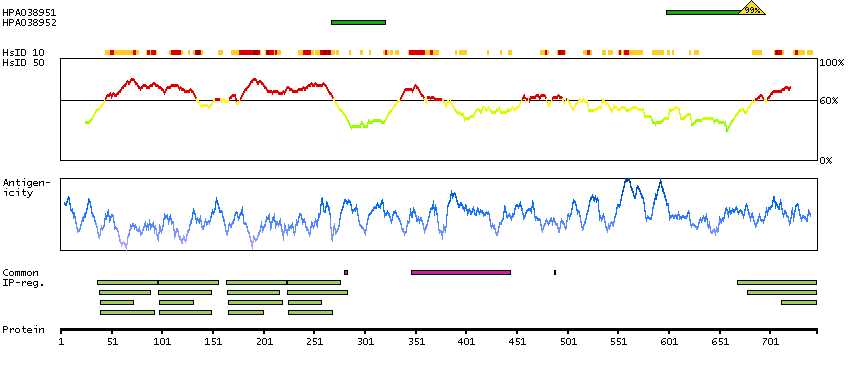
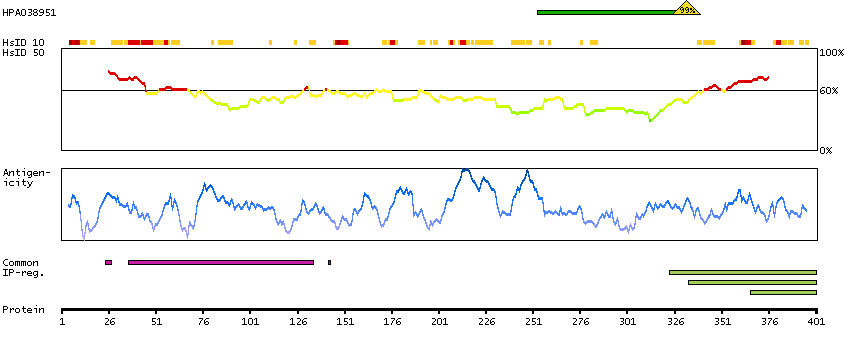
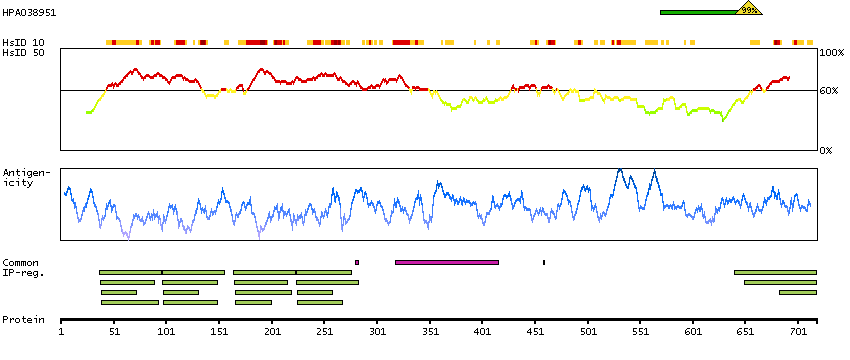
This gene encodes a cytoskeletal LIM protein that binds to actin filaments via a domain that is homologous to erythrocyte dematin. LIM domains, found in over 60 proteins, play key roles in the regulation of developmental pathways. LIM domains also function as protein-binding interfaces, mediating specific protein-protein interactions. The protein encoded by this gene could mediate such interactions between actin filaments and cytoplasmic targets. Alternatively spliced transcript variants encoding different isoforms have been identified. [provided by RefSeq, Jul 2008]